
Last updated on 30 May 2026
Announcement
This documentation will no longer be maintained.
For any professional services, click here.
I've updated the CGNAT section with RouterOS v7 EIM-NAT config; this is the best possible CGNAT configuration that can exist on RouterOS at the time of writing this.
This guide provides configuration instructions for MikroTik RouterOS, but the principles can be applied to other Network Operating Systems (NOSes) as well. The guide will be updated regularly as new technologies, use cases, and more efficient configurations are discovered.
Many ISPs around the globe use MikroTik RouterOS to provide access to their customers via BNGs over PPPoE and for various other roles such as edge routers. In this guide, I will explore common issues and solutions along with best practices.
This guide is also available on the APNIC Blog, however the version there is obsolete. I recommend you follow the source here for the most up-to-date information.
A brief history of this project
- The configuration was first tested and deployed on AS135756 (small-sized ISP) with its proprietor Varun Singhania.
- In 2021-22, I tested the configuration further as a downstream customer on AS132559 (IP Transit provider & medium-sized ISP), where I was able to assess the impact and config changes both as an end-user and a consultant.
- From 2022 onwards, I test the configurations on my own network (AS149794), including the firewall rules, to ensure it would work in any environment as long as the instructions are followed. The tests confirmed that the configuration does not disrupt layer 4 protocols or cause problems for end-users in the last mile.
A few things to keep in mind
- RouterOS is based on the Linux Kernel. As of RouterOS v7.14.2 it still uses legacy iptables for packet filtering instead of nftables, which has a negative impact on performance.
- The guide will be focused on RouterOS v7 as it is the current version of RouterOS.
- This guide assumes the reader has a basic understanding of typical use cases and technologies/protocols used in an ISP/Telco production environment.
- This guide focuses on layer 2-4 configuration (and occasionally up to layer 7) by following various RFCs and BCOPs. It is not a network architecture guide, for which Kevin Myers’s guide is recommended.
- Most (virtually everything) on this article has been tested on RouterOS v7.14.2 (stable + 7.14.2 RouterBOARD firmware).
Basic Router Terminology and overview
- An edge or border router is an inter-AS router that is used for connecting different networks, such as transit, IXP, or PNIs.
- It is important to keep an edge router stateless i.e. without connection tracking (stateful firewall filter rules or NAT), to avoid performance issues and vulnerability to DDoS attacks.
- Do not use an edge router for customer delegation, as it will become stateful.
- Do not confuse an edge router with a Provider Edge router, which is an MPLS-specific terminology.
- A core router is not typically present in modern networks that follow a collapsed core topology.
- However, some people may incorrectly refer to an edge router as a core router due to linguistic, cultural reasons, or misinformation.
- BNGs, also known as access layer routers, are used for customer delegation tasks such as PPPoE, DHCP, and CGNAT. They are stateful in nature. Some people may also refer to them as BRAS or NAS (Network Access Servers), all of which are synonyms in my opinion.
General Configuration Changes
Below are the general guidelines that should be applied on all MikroTik devices for optimal performance and security.
- Upgrade RouterOS and the RouterBOARD firmware to the latest stable (or long-term if available) v7 releases, Use this command to enable firmware auto upgrade: “/system routerboard settings set auto-upgrade=yes”. Remember to reboot the router twice after the RouterOS upgrade to ensure firmware gets automatically upgraded.
- Implement basic security measures, including reverse path filtering and enabling TCP SYN cookies, for which the latter two are found in IP>Settings.
- For rp-filter use loose mode when a device is behind asymmetric routing or when in doubt, use strict mode when a device is behind symmetric routing.
IPv6
IPv6 Router Advertisements (RA) are used for SLAAC and/or DHCPv6 and in MikroTik it is called Neighbor Discovery (ND) which is a bit confusing as ND is an umbrella encompassing various protocols and behaviours and not only RAs.
IPv6 RA (ND) is enabled by default for all interfaces on RouterOS. This should be disabled to prevent sending RAs randomly out of interfaces that you do not use SLAAC on and for security reasons such as preventing someone from receiving an IPv6 address by connecting a host to a specific port or VLAN along with reducing unnecessary BUM traffic in your network. We disable it using this command:
“/ipv6 nd set [ find default=yes ] disabled=yes”
You can enable IPv6 RA on a per-interface basis as and when required, i.e. if you set “advertise=yes” for an interface via IPv6>Address, then you need to configure RA/ND for that interface like the example below:
“/ipv6 nd add interface=Management_VLAN”
Interface Lists
Interface lists help us simplify firewall rule management by enabling us to refer to an entire list in a single rule instead of multiple rules for every interface.
An interface list should only contain layer 3 (L3) interfaces which is an interface with IP addressing attached to it, such as a physical port, L3 sub-interface VLAN, L3 bonding interface or GRE interface.
The following are basic guidelines for which lists to create and what should be included on those lists:
- “WAN” interface list should contain those interfaces used for connecting to transit, PNI, IXP, upstream peering.
- “LAN” interface list should contain those interfaces used for downstream connectivity to your retail customers or IP Transit customers etc. You should include “dynamic” interfaces to account for PPPoE clients on BNGs.
- “Intra-AS” interface list should contain those interfaces used for connecting one device to another device within the same network such as redundant connectivity between two routers horizontally.
- “Management” interface list should contain those interfaces used exclusively for management.
- Do not add bridge members individually into any list as they are purely Layer 2 (L2) interfaces.
It is however, important to note: When you are using bridges (which is discussed later in this article), the interface placements depend on how you set up the bridge – If you’re using a single bridge with physical/bonding interfaces as bridge members without any VLAN configuration, then the bridge will be a member of “LAN”. But if you are using VLANs on top of the bridge, then place the VLANs into their appropriate LAN/Intra-AS/Management list based on your local network topology. For example:
“Management VLAN” will be in the management list, or VLAN123 will be in the “intra-AS” or “LAN” list.

Connection Tracking
- Disable connection tracking on the edge router and enable loose TCP tracking on all routers using the following commands:
“/ip firewall connection tracking set enabled=no”
“/ip firewall connection tracking set loose-tcp-tracking=yes” - Use the recommended connection tracking timeout values to improve stability and performance, especially for UDP traffic like VoIP and gaming. If necessary, upgrade the router’s RAM to accommodate these values.
/ip firewall connection tracking
set icmp-timeout=30s tcp-close-wait-timeout=1m tcp-fin-wait-timeout=2m tcp-last-ack-timeout=30s tcp-syn-received-timeout=1m tcp-syn-sent-timeout=2m tcp-time-wait-timeout=2m udp-stream-timeout=2m udp-timeout=30sMiscellaneous
- Give the router an accurate system clock by enabling the Network Time Protocol (NTP) client and specifying a reliable NTP server such as this example:
“/system ntp client set enabled=yes server-dns-names=time.cloudflare.com”
MTU
To ensure reliable network performance, it is essential to configure the MTU consistently across all devices in the path in both L2 and L3. Inconsistent MTU configurations can result in dropped frames or strange behaviours. Additionally, it is essential to minimize IP fragmentation, properly deploy RFC4638, and ensure PMTUD is working for both IPv4 and IPv6. This will help to ensure reasonable auto-detected TCP MSS negotiation values.
Jumbo frames are ideally the way to go about MTU configuration as it’s future-proofing your network for whatever protocols you may throw at it. You should encourage your provider, peers, and customers to also configure jumbo frames on their network.
Bigger frames = more data per frame, meaning less frames required to transmit data, less CPU/resource utilisation required as packets per second flow will decrease.
Guidelines
Layer 2 MTU
L2 MTU, also known as the “media MTU” should be configured to the maximum supported value on physical interfaces such as Ethernet ports, SFP and wireless interfaces. This applies to any networking hardware, including routers, switches, and hypervisors. The maximum supported value may vary by vendor or model, but that is okay as the L3 MTU will handle the actual packet size negotiation.
However, it is important to note that, you must ensure the interfaces all have consistently maximum values to minimise the number of MTU profiles on the device – The switch chip or ASIC has limited support for n number of MTU profiles which if exceeded could hurt performance or lead to undefined behaviours.
By properly configuring the L2 MTU, you can run any protocol you want (such as VXLAN, MPLS, VPLS, or WireGuard) and still have an MTU far greater than 1500 for layer 3 packets, thereby avoiding fragmentation completely on the overlay, intra-as.
Example:
- Edge router (L2 MTU 9216) > BNG (L2 MTU 9216) > PE router (L2 MTU 9216) > Wireless AP (Bridged mode, often carries 9216 or similar L2 MTU) > Customer edge router (L2 MTU for WAN 9216)
- Edge router (L2 MTU 9216) > BNG (L2 MTU 9216) > PE router (L2 MTU 9216) > OLT (Bridged mode, often carries 9216 or similar L2 MTU) > Customer edge router (L2 MTU for WAN 9216)
Layer 3 MTU
Configure it to 9k MTU, strictly for all physical ports (ethernet, SFP etc). If there is any L2 overhead, such as on a layer 3 sub-interface VLAN, the system will automatically subtract from the L2 MTU and will show us the subtracted L2 MTU, so you can adjust layer 3 MTU accordingly.
The basic gist of this is, we use the 9k L3 MTU on intra-AS and even inter-AS physical interfaces, unless explicitly your peer doesn’t support 9k.
This allows your downstream transit customers to talk to your network and your customers in jumbo frames – For which, you should inform your customer if you’ve enabled jumbo frames for them, their L3 MTU must match your L3 MTU.
But if for example, you are configuring an interface towards your transit or IXP, then you should ask your provider if they support >1500 MTU and configure accordingly. Some transit providers and IXPs supports 9000 MTU, so we take advantage of that when possible.
Some things to be careful of:
- If using Stacked VLANs (QinQ), both S and C VLANs should have equal L3 MTU.
- If your customer equipment does not support high jumbo frame, then simply configure your L3 MTU to match theirs, which is usually 1500.
Example:
- Edge router (L3 MTU 9k) > BNG (L3 MTU 9k) > PE router (L3 MTU 9k) > Wireless AP (bridged mode and permits jumbo frames above 9k) > Customer edge router (L3 MTU for WAN will be 9k, assuming you configure 9k MTU on the S-C VLAN on the BNG)
- Edge router (L3 MTU 9216k) > BNG (L3 MTU 9216k) > PE router (L3 MTU 9k) > OLT (L3 MTU 9k) > (L3 MTU for WAN will be 9k, assuming you configure 9k MTU on the S-C VLAN on the BNG)
MTU can be mixed and match network-wide, but should never mismatch. PMTUD exists for a reason, I have built networks where I had 9k in some paths, 8k in some paths, 1500 in some paths, differences may be on physical interfaces where a sub-interface is configured on top of the physical interface (such as a bridge, or L3 subinterface VLANs on top of the bridge). With proper planning and thought, you shouldn’t have problems with 9k MTU mixed in with lower sized MTU.
The screenshots below are for references to give you an idea of what MTU mix/match (but never mismatch) looks like, this is based on a network I built from scratch. Ether1 is 1500 L3 MTU because it’s my MGMT/OOB port, the other physical ports are all 9k L3 MTU and maxed L2 MTU. The LACP bonding interfaces are my intra-as interfaces connected to my backbone routers, and 9K is configured on their side as well. The VPLS is jumbo frames MPLS network-wide to ensure I can carry as much VLANs as I want, as much L2VPN customers as I want without any problems for jumbo frames.
The VLANs on top of the bridge (excluding the pe01) are tagged to the VPLS circuit (also member of bridge) which are configured to 1500 MTU as these are layer 3 terminating interfaces, as my residential customers behind these VLANs, don’t have routers with jumbo frames, so 1500 makes sense. But if for example, on VLAN1501, one day, I moved all customers to jumbo frames 9k enabled routers? Then I simply change the MTU config on my VLAN interface right here, as the underlying transport network is already enabled with jumbo frames from day one.


MTU Scripts
You can automate the MTU configuration using the scripts below. Please run each one separately as I didn’t put delays in between preventing synchronisation, but be mindful to manually configure L2, L3 MTU and advertised L2 MTU for VPLS/Other PPP interfaces.
#Run the ethernet MTU script first before the others#
#Script to autoconfigure max L2/L3 MTU on ethernet ports#
/interface ethernet
:foreach i in=[find] do={
set $i l2mtu=[/interface get $i max-l2mtu]
set $i mtu=[/interface get $i max-l2mtu]
}
#Script to autoconfigure max L3 MTU on Layer 3 sub-interface VLAN#
/interface vlan
:foreach i in=[find] do={
set $i mtu=[/interface get $i l2mtu]
}
#Script to autoconfigure max L3 MTU on Bonding interfaces#
/interface bonding
:foreach i in=[find] do={
set $i mtu=[/interface get $i l2mtu]
}
#Script to autoconfigure max L3 MTU on VXLAN#
/interface vxlan
:foreach i in=[find] do={
set $i mtu=[/interface get $i l2mtu]
}
#Script to autoconfigure max L2/L3 MTU on Wireless interfaces#
/interface wireless
:foreach i in=[find] do={
set $i l2mtu=2290
set $i mtu=2290
}
#Linux Bridge Approach
A Linux bridge is a kernel module that acts as a virtual network switch and is used to forward packets between connected interfaces (also known as bridge ports or members). Many network operators do not follow MikroTik’s official guidelines to properly implement L2/3 using a bridge, which results in degraded performance as hardware offloading and/or bridge Fast Path/Fast Forward becomes unusable along with the inability to perform L2 filtering.
Linux driven hardware such as MikroTik or even Cumulus Linux devices rely heavily on Linux DSA. Linux DSA, Bridge, vlan-aware bridge is a very complex vast topic that currently doesn't have a comprehensive network engineer oriented documentation, I will try to work with a buddy of mine to write a new blog post to deep diving the Linux DSA/Bridge architecture and what it means for network engineers. Until then, just keep in mind that, for layer 3 offloading to work correctly, you need single bridge for all downstream interfaces and use the vlan-filtering to segregate them as "access ports" on a router, and ocassionally trunk port as well depending on your topology and use-case. This means if you have a box, and the box has only one ASIC, then only one bridge can exist for physical ports/interfaces/LACP etc. However, you can create a loopback bridge, no problem.
To maximize performance benefits and give you L2 filtering capabilities, it is recommended by MikroTik to create a single bridge per device with all downstream (and intra-AS) interfaces (physical, LACP bonding etc) as bridge members. Tagged/untagged VLANs and hybrid VLANs can be configured using bridge VLAN filtering. Refer to vendor guidelines for model-specific configuration instructions.
If you created an LACP bonding interface between two routers (or switches) for redundancy, you can add the bond interface into the same bridge as a bridge member, where in turn either the bridge itself or the L3 sub-interface VLANs will be an interface list member depending on your topology as discussed in the previous interface lists section.
The management port on newer MikroTik device is a dedicated port connected to the CPU instead of the ASIC, similar to traditional networking devices from Cisco or Juniper. In such cases, the management port will be fully indepdent from any bridge, with its own indepedent VRF. However, if for example you’re transporting managment VLAN for a downstream device from a dowsntream port, example SFP+12, then in this case, SFP+12 will be member of the bridge with VLAN config on the bridge as usual.
A separate bridge can also be created as a loopback interface without impacting physical interface performance. You can assign the “.0” IPv4 address to this interface along with the “::” IPv6 address of an IPv6 subnet for management, testing purposes or for using as the loopback IPs with OSPF.
Below is a sample configuration from a CCR1036 router using MikroTik guidelines along with sample interface lists:
#Layer 3 configuration such as IP addressing is attached to these interfaces#
/interface vlan
add interface=bridge1 mtu=10218 name="Main VLAN" vlan-id=20
add interface=bridge1 mtu=10218 name="Management VLAN" vlan-id=10
/interface bridge
add frame-types=admit-only-vlan-tagged name=bridge1 vlan-filtering=yes
#Loopback interface#
add arp=disabled name=loopback protocol-mode=none
/interface bridge port
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether1 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether2 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether3 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether4 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether5 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether6 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether7 pvid=20
add bridge=bridge1 frame-types=admit-only-untagged-and-priority-tagged interface=ether8 pvid=10
/interface bridge vlan
add bridge=bridge1 comment="Main VLAN" tagged=bridge1 vlan-ids=20
add bridge=bridge1 comment="Management VLAN" tagged=bridge1 vlan-ids=10
#Attaching IP addressing to the interfaces#
/ip address
add address=100.64.2.1/24 interface="Main VLAN" network=100.64.2.0
add address=103.176.189.0 comment="Public Loopback" interface=loopback network=103.176.189.0
add address=100.64.3.1/25 interface="Management VLAN" network=100.64.3.0
#Example for interface lists#
/interface list member
add interface="Main VLAN" list=LAN
add interface="Management VLAN" list="Management Interfaces"R/M(STP)
I will not deep dive into how STP works, as that is outside the scope of a guide post like this one. However, a few quick things to keep in mind:
- MikroTik allows us to selectively enable/disable STP/BPDU per-port if required. This may be needed in your network with complex layer 2 designs.
Multicast traffic on the bridge
I personally had a few challenges with multicast traffic/IGMP Snooping best practices, for which I had to reach out to MikroTik support for some clarity. Below are a few basic guidelines to follow based on what I gathered from MikroTik docs and their support team. This is of utmost importance for networks that makes use of multicast routing and traffic for their IPTV services and similar.
- Be mindful of IGMP Snooping (and IGMP Proxy/PIM) limitations such as tagged VLAN, and features depending on your local network topology.
- Keep in mind that IPv6 SLAAC will break if you enable multicast querier, for which, you need RouterOS v7.7 onwards to work around this.
- In a layer 2 network if you are using IGMP Snooping, it should be enabled on all the bridges (devices) involved.
- You can also enable IGMP multicast querier on all the bridges, only one will get elected with the rest acting as failover in case a device fails.
- If you are using PPPoE then there’s no such thing as true multicast, because whilst it may multicast on layer 3, it will not be true multicast on layer 2 due to the nature of PPPoE which is a tunnel over layer 2. If you are using DHCP (preferably) or IPoE, then this issue does not apply.
Prefix size for PTP links
IPv4
I have noticed a lot of operators talking about how short they are on IPv4 addresses – Yet for unknown reasons they like to waste 2 extra addresses for every PTP or inter-router link by using a /30. Please, stop doing that and start using /31s for PTP links as per RFC3021.
However, RouterOS v6+v7 does not support /31 natively, the following is how we do it.
Example below:
Prefix: 103.176.189.0/31
#MikroTik to MikroTik PTP#
#Router A#
/ip address
add address=103.176.189.0 interface=ether1 network=103.176.189.1 comment="/31 Example"
#Router B#
/ip address
add address=103.176.189.1 interface=ether1 network=103.176.189.0 comment="/31 Example"#Cross vendor PTP#
#Router A Cisco/Juniper/Huawei etc#
interface eth2 address 103.176.189.0/31
#Router B MikroTik side#
/ip address
add address=103.176.189.1 interface=ether1 network=103.176.189.0 comment="/31 Example"IPv6
As per RFC6164, it is advised to use /127s on PTP links to avoid various forms of network attacks described in the RFC.
However, for ease of management and subnetting, I would advise not to subnet longer (smaller) than a /64. Please click here to learn more about IPv6 architecture and subnetting plan.
Note that on MikroTik, /127s do not work with BGP for unknown reasons and hence the longest prefix size we can use would be a /126.
Example below:
Prefix: 2400:7060::/126
#Advertise=no because we aren't using SLAAC#
/ipv6 address
add address=2400:7060::1/126 advertise=no comment="Peering with Transit" interface=ether1
However, if you look closely, you might’ve noticed that I avoided using the initial zeroes leading interface ID “2400:7060::/126″ and instead used “2400:7060::1/126″. The reason for this is, that in some routers, using the “::” (all leading zeroes) interface ID (address) on a link could cause strange behaviours.
Routing loops with RFC6890 space
I have observed that in most of the networks, including my own personal home lab (AS149794), I find a lot of traffic where source IP = my end hosts or CPE WAN IP (either it is CGNAT IP or public IP), but destination IP = unused RFC6890 blocks. This is why I (and MikroTik themselves) created a forward rule to drop RFC6890 from escaping to WAN.
Now let us step back and think about this: The majority of the ISPs do not implement these filter rules, which means that traffic from customers whereby dst-IP=RFC6890 is forwarded from their CPE to the BNGs, and from there the underlying L3/L2 paths will carry it all the way to the edge router, where further, goes towards your transit or peers if there is a default route. If there is no default route or more specific route for any given dst-IP matching RFC6890 blocks, it would simply loop back and forth until the TTL expires, which means wasted resources, CPU and bandwidth when your network is at scale and you have thousands of customers. So in order to solve this with a quick fix, I derived a simple yet effective solution – Route RFC6890 blocks to blackhole.
We route all RFC6890 space to black hole directly on the edge routers for well edge cases, but we will also do the same on the BNGs directly.
It will not impact your use of the private space for any given interface/servers etc – Because remember, more specific prefixes always win and hence your private /24s etc will always be preferred over the less specific /10 for example and hence will be accessible. Someone on the MikroTik forum has discussed this a bit, in the past.
IPv4
#RouterOS v7#
#Copy and paste these on both Edge and BNG routers#
/ip route
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=0.0.0.0/8
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=172.16.0.0/12
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.168.0.0/16
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=10.0.0.0/8
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=169.254.0.0/16
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=127.0.0.0/8
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=224.0.0.0/4
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=198.18.0.0/15
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.0.0.0/24
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.0.2.0/24
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=198.51.100.0/24
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=203.0.113.0/24
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=100.64.0.0/10
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=240.0.0.0/4
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.88.99.0/24
add blackhole comment="Blackhole route for RFC6890 (limited broadcast)" disabled=no dst-address=255.255.255.255/32#RouterOS v6#
#Copy and paste these on both Edge and BNG routers#
/ip route
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=0.0.0.0/8
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=172.16.0.0/12
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.168.0.0/16
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=10.0.0.0/8
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=169.254.0.0/16
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=127.0.0.0/8
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=224.0.0.0/4
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=198.18.0.0/15
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.0.0.0/24
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.0.2.0/24
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=198.51.100.0/24
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=203.0.113.0/24
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=100.64.0.0/10
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=240.0.0.0/4
add type=blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=192.88.99.0/24
add type=blackhole comment="Blackhole route for RFC6890 (limited broadcast)" disabled=no dst-address=255.255.255.255/32IPv6
#RouterOS v7#
#Copy and paste these on both Edge and BNG routers#
/ipv6 route
add blackhole comment="Blackhole route for RFC6890" disabled=no dst-address=::1/128
add blackhole comment="Blackhole route for RFC6890" disabled=no dst-address=::/128
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=64:ff9b::/96
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=::ffff:0:0/96
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=100::/64
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=2001::/23
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=2001::/32
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=2001:2::/48
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=2001:db8::/32
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=2001:10::/28
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=2002::/16
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=fc00::/7
add blackhole comment="Blackhole route for RFC6890 (aggregated)" disabled=no dst-address=fe80::/10#In RouterOS v6, IPv6 blackhole is not supported#QoS and Bufferbloat control
Going forward from 2023 onwards with RouterOS v7 (or any modern OS), based on the immense amount of work, data, and results published by Dave Täht on the subject of QoS/QoE and more specifically the main problem with this domain i.e. bufferbloat, I would recommend using FQ_Codel network-wide as the default queueing algorithm. The main reason to opt for FQ_Codel is primarily because it was designed for backbone network usage, such as ISPs, Telcos and carriers, compared to the end-user-oriented CAKE.
This means configuration wise, you apply the FQ_Codel queueing to all your physical ports and wireless interfaces across all your network devices. And ensure for customer queueing the same queue type is used.
An important point to note is the default values of FQ_Codel out-of-the-box are good up to 40Gbps physical interfaces. This means that if a single physical port is carrying more than 40Gbps traffic, you will need to tweak a custom FQ_Codel profile for that specific port.
Example configuration on a CCR1036:
/queue type
add kind=fq-codel name=FQ_Codel
/queue interface
set ether1 queue=FQ_Codel
set ether2 queue=FQ_Codel
set ether3 queue=FQ_Codel
set ether4 queue=FQ_Codel
set ether5 queue=FQ_Codel
set ether6 queue=FQ_Codel
set ether7 queue=FQ_Codel
set ether8 queue=FQ_Codel
set sfp-sfpplus1 queue=FQ_Codel
set sfp-sfpplus2 queue=FQ_CodelIn addition to network backbone FQ_Codel implementation, you can also consider deploying an open-source bufferbloat killer traffic shaping device using LibreQoS.
Below is a screenshot of the test results from this tool on a wireless ISP network that I architected and implemented myself from the ground up. I should note that, I implemented everything from this guide + other design considerations which includes network-wide FQ_Codel config, in my case there is no LibreQoS-like device as I wanted a simpler network topology, and the end result below is a result that’s better than even some fibre networks on PON out there in the market.
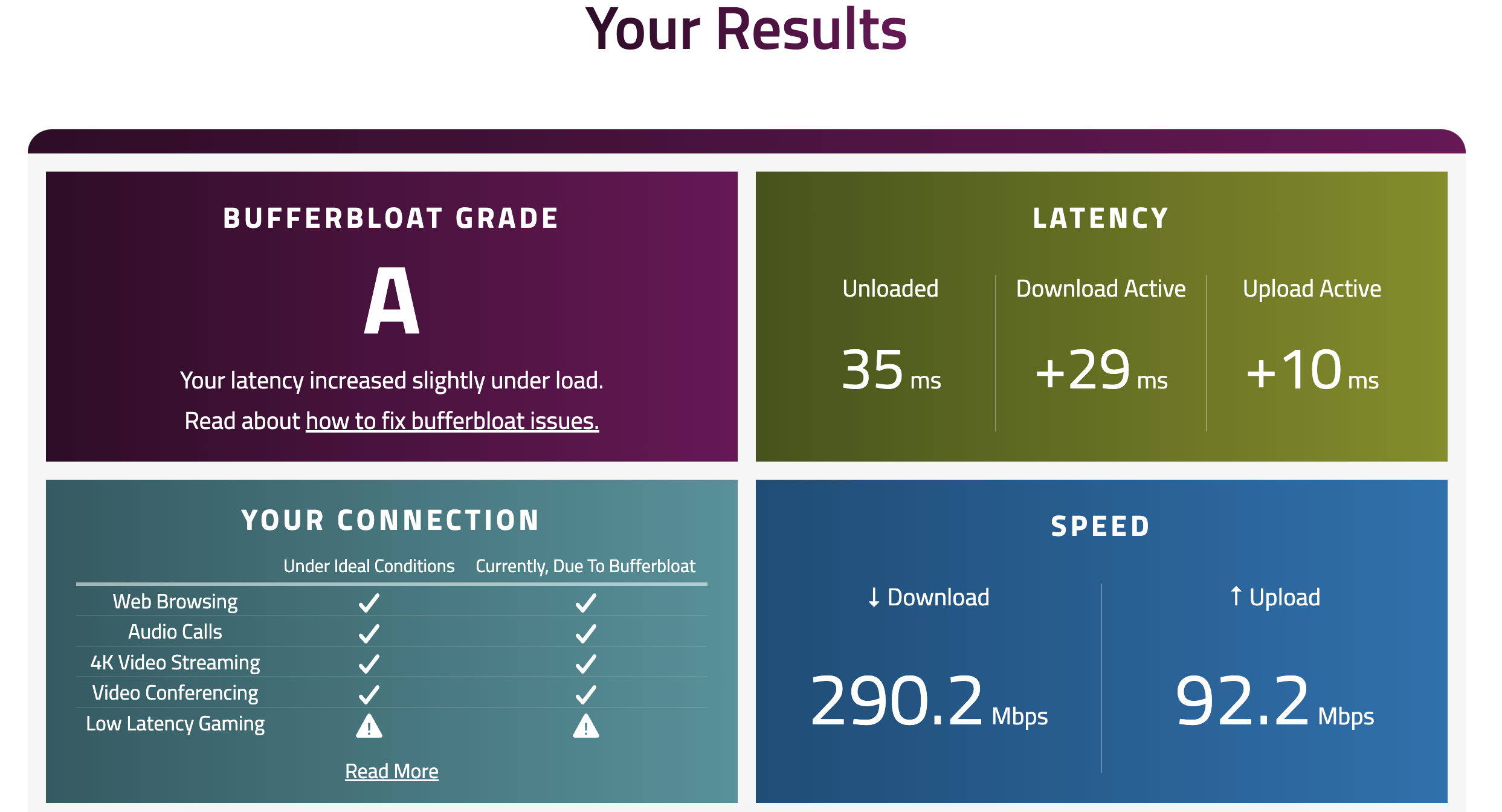
For BNG
PPPoE
Issues
- Packet fragmentation due to non-standard 1500 MTU/MRU
- Typically, ISPs use 1492 or 1480 or some other strange MTU size
- Both BNG device and customer router need to make use of hacks like TCP MSS Clamping to work around this
- PMTUD is simply unreliable as per RFC 8900
- Gets worse with CGNAT because remote end-points cannot determine the MTU of your PPPoE customer behind it
- Lack of proper routing for PPPoE Clients (Interfaces or Inter-VLANs)
- Most assume that using a single profile for different PPPoE Servers running on different interfaces will work fine
Solutions
- The real long term solution is to migrate to DHCP to completely avoid all performance and MTU issues that are exclusively only an issue on PPPoE and similar encapsulation protocols.
- Deploy RFC 4638
- Keep in mind that in a network, MTU affects the whole path of L2/L3 devices whether physical or virtual, as long as you follow the MTU section above, you should be good
- Simply set MTU and MRU to 1500 inside PPPoE Server on the BNG
- However, if you are interested in the whole jumbo frames to your peers/PNI/IXP etc – You can configure MTU/MRU to fixed 9000 bytes, the reason for 9000 nytes for inter-AS traffic is explained here
- In order for this to work correctly you need to strictly follow the MTU section
- If using Wireless APs, then it would 2290-8=2282 bytes
- However, if you are interested in the whole jumbo frames to your peers/PNI/IXP etc – You can configure MTU/MRU to fixed 9000 bytes, the reason for 9000 nytes for inter-AS traffic is explained here

- Disable (and delete!) TCP MSS Clamping rules inside IP>Firewall>Mangle
- Why set some arbitrary value when you can let the engine determine automatically to ensure optimal performance?
- MikroTik has long since allowed automatic TCP MSS ClampingMake use of PPP>Profile>Default* to enable TCP MSS Clamping directly on the PPPoE engine. This will do the work for any customer whose MTU/MRU is less than 1500.
- On the customer side, not all routers can take advantage of RFC4638, such as TP-Link, Tenda etc. For them, MTU will remain capped at 1492.
- The 1492 limitation on their end won’t cause issues with packet fragmentation as packets would fragment at the source (their routers) before it exits the interface and hits the BNG and TCP Clamping on PPPoE engine takes care of anything coming in from the outside world toward the customer
- I have observed 1500 MRU when pinging from the outside world. Suggesting some of these consumer routers support 1500 MRU
- If they are using MikroTik, pfSense, VyOS etc, they can take advantage of RFC4638 aka 1500 MTU/MRU for their PPPoE Client
- Some ONT/ONU devices have strange behaviour for MTU negotiation where they simply do not allow RFC4638 to work (even in bridge mode), only a few brands like GX, TP-Link, and Huawei have been found to be flawless in my personal testing.
- Why set some arbitrary value when you can let the engine determine automatically to ensure optimal performance?
Verify MTU config
If you have properly configured MTU and MSS Clamping as per the steps above, then you should see the following results when testing from customer-side using this tool:
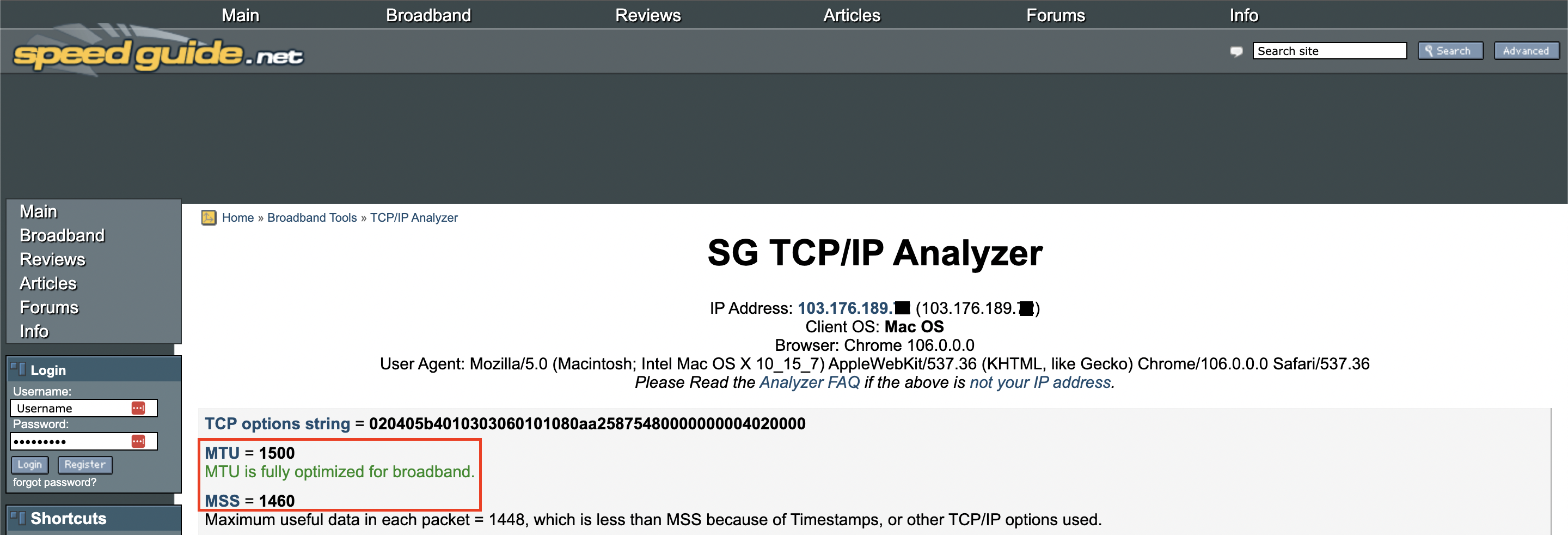
Extra Note on PPPoE
- Create a single CGNAT pool on a per BNG basis and you can use it for n Number of PPPoE Servers on n number of interfaces
/ip pool
add name=CGNAT_Pool comment="100.64.0.0-9 is reserved for each PPPoE Server Gateway/Profile" ranges=100.64.0.10-100.127.255.255- Here we are reserving 100.64.0.0-9 for gateway IPs on a per-interface/PPPoE server basis, assuming we only have 10 VLANs/Interfaces
- Reserve as per your local requirements
- Here we are reserving 100.64.0.0-9 for gateway IPs on a per-interface/PPPoE server basis, assuming we only have 10 VLANs/Interfaces
- Local Address in PPP Profile = Gateway IP address
- One common mistake is using the router’s public IP from the WAN interface as the local address, which I’ve seen could lead to issues like traceroute failures or some strange packet loss, you should be using an address that does not exist in IP>Address
- Each PPPoE Server needs unique profile/gateway in order to allow inter-VLAN communication between CPEs (which is needed to allow two customers behind a NATted IP to play a P2P Xbox game with each other on different VLANs) and will also ensure a clean network approach
- If you have 100 PPPoE Servers, there should be 100 unique PPP Profiles with unique local addresses for each
- Something like this for two servers:
/ppp profile
add change-tcp-mss=yes local-address=100.64.0.1 name=profile1 remote-address=CGNAT_Pool use-upnp=no
add change-tcp-mss=yes local-address=100.64.0.2 name=profile2 remote-address=CGNAT_Pool use-upnp=no
/interface pppoe-server server
add authentication=pap default-profile=profile1 interface=vlan20 keepalive-timeout=disabled max-mru=1500 max-mtu=1500 one-session-per-host=yes service-name=server1
add authentication=pap default-profile=profile2 disabled=no interface=vlan21 keepalive-timeout=disabled max-mru=1500 max-mtu=1500 one-session-per-host=yes service-name=server2CGNAT
Issues
- The majority of ISPs are using RFC1918 subnets for CGNAT and will clash with subnets on the customer site
- Breaks NAT Traversal for protocols like IPSec, FTP etc
- Poor config, that breaks P2P traffic, kills the end-to-end principle
- Lack of hairpinning breaks inter-client P2P traffic
- Lacks EIM-NAT (newly added by MikroTik)
- Routing Loops will occur for any traffic coming from the outside destined towards the public IP pools that aren’t related to NATted traffic
Solutions
- Make use of the 100.64.0.0/10 subnet as it’s meant for CGNAT usage to prevent clashing on the customer site
- Enable all the NAT traversal Helpers on the NAT box, as shown below.

- Use the follow config template going forward (2024 onwards), which includes IPsec passthrough, EIM-NAT, Netmap functionality for 1:Many with consistent 1:1 port mapping. Please note rule order is important, the following template has accounted for rule order to capture packets correctly. We will assume “103.176.189.0/30” to be our public CGNAT pool.
/ip firewall nat
#EIM-NAT#
add action=endpoint-independent-nat chain=srcnat comment=EIM-NAT out-interface-list=WAN protocol=udp randomise-ports=no src-address=100.64.0.0/10 src-port=1024-65535 to-addresses=103.176.189.0/30
add action=endpoint-independent-nat chain=dstnat comment=EIM-NAT dst-address=103.176.189.0/30 dst-port=1024-65535 in-interface-list=WAN protocol=udp randomise-ports=no to-addresses=100.64.0.0/10
#Required as EIM-NAT in MikroTik doesn't support all layer 4 Protocols#
add action=netmap chain=srcnat comment="CGNAT Rule" dst-address-list=!not_in_internet ipsec-policy=out,none out-interface-list=WAN src-address-list=cgnat_subnet to-addresses=103.176.189.0/30
#Hairpinning rule to ensure P2P traffic works for all clients behind the CGNAT#
add action=masquerade chain=srcnat comment="Hairpin for CGNAT clients" dst-address-list=cgnat_subnet src-address-list=cgnat_subnet- Here cgnat_subnet=address list containing CGNAT subnets i.e. 100.64.0.0/10
- dst-address-list=!not_in_internet is self-explanatory, anything destined towards private subnets shouldn’t be NATted towards WAN
- The hairpinning will allow customers to talk to each other using their CGNAT IP, Xbox makes use of this and is mentioned in RFC 7021.
- Avoid Deterministic NAT, the above configuration allows P2P traffic initiated from the inside to be reachable from the outside with various applications that make use of ephemeral ports/UDP NAT punching/STUN etc
- We were able to successfully seed the official Ubuntu Torrent behind the CGNAT with the above configuration, which can mean only one thing: P2P networking from in-bound established works!

- We tried with src nat as action for src NAT chain but it resulted in the NATted public IP constantly changing on the customer side and breaking things
Below is what MikroTik support had to say about netmap vs src nat as action for src nat chain

- Now we fix routing loops for the CGNAT public pool
/ip route
add blackhole comment="Blackhole-CGNAT pool" dst-address=103.176.189.0/30Subscription Ratio Recommendation
In my extensive testing and observations, when using the above parameters and steps, I was able to have 200 users behind a /30 without any known complaints from them. BitTorrent worked as expected too, this is likely due to the obvious fact that not all users out of 200 will max out 65k connections and hence use up all the IP:Port combination. Where will you find a CPE that can handle 65k NAT entries anyways?
So tl;dr you can use a /30 per 200 users as long as you follow the steps properly and also to be future-proof and safe, ensure you provide IPv6 as well.
End Result

Logging compliances for government and regulatory requirements
For CGNAT logging for compliances purpose, you can use Traffic Flow which also adds additional option for NAT events logging in the configuration.
IPv6
Issues
- Addressing may not be optimally subnetted/broken down
- ISP may only have something like a single /48 with 5000 customers downstream which exceeds possible /56s out of the /48
- Not following the proper guidelines for IPv6 deployment
- Lack of persistent assignment feature on MikroTik
- This applies to the majority of ISPs even though they may use Cisco, Juniper etc which supports persistent assignment configuration
- Not properly ensuring that the customer’s WAN side gets a proper single /64
- Forcing the customer to have only a single /64 on the LAN side instead of /56
- MikroTik IPv6 RADIUS does not work correctly
Solutions
- A proper IPv6 architecture and subnetting plan should be implemented
- However, the logic is simple
Ensure customers get /64 WAN side and /56 LAN side for home users
Ensure customers get /64 WAN side and /48 LAN side for enterprise/SMEs/DC etc
- However, the logic is simple
- Ensure you request for appropriate prefix allocation based on your customer base from your Regional Internet registry/Local Internet registry
- Follow the proper guidelines and BCOPs
- I came across a solution for the lack of persistent assignment on MikroTik, simply use the following script and schedule it to run every five minutes:
#Please don't be stupid enough to set owner=Daryll#/system script
add dont-require-permissions=no name=PPPoE-IPv6-Persistent owner=Daryll policy=ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon source=\
"/ipv6 dhcp-server binding;\r\
\n:foreach i in=[find server~\"pppoe\"] do={\r\
\n make-static \$i;\r\
\n set \$i comment=[get \$i server];\r\
\n set \$i server=all;\r\
\n}"
Use the scheduler for automating it:/system scheduleradd interval=5m name=PPPoE-IPv6-Persistent-AutoUpdate on-event=PPPoE-IPv6-Persistent policy=ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon start-time=startup
Now I will cover a simple configuration use-case where a BNG has exactly 1000 customers. The goal here is to ensure that the WAN side of each customer gets a /64 and the LAN side gets a /56.
- Disable redirects
/ipv6 settings set accept-redirects=no - Next need to create two separate pools, one for WAN and one for the LAN side of the customer
/ipv6 pool
add name=Customer-CPE-LAN prefix=2405:a140:8::/46 prefix-length=56
add name=Customer-CPE-WAN prefix=2405:a140:f:d400::/54 prefix-length=64- Here, prefix-length specifies what prefix length the customer gets, which in this case as per standards, we are giving the WAN side a /64 and the LAN side a /56
- And finally, configure the pools to each PPPoE Profile as below
/ppp profile
set *0 dhcpv6-pd-pool=Customer-CPE-LAN remote-ipv6-prefix-pool=Customer-CPE-WAN
add name=profile2 dhcpv6-pd-pool=Customer-CPE-LAN remote-ipv6-prefix-pool=Customer-CPE-WAN- Remote IPv6 prefix is for the WAN side of the customer
- DHCPv6 PD Pool is for the LAN side of the customer

That’s it, now the customers will dynamically get a routed /64 and routed /56 for WAN and LAN sides respectively.
Verify IPv6 config
If you have properly configured IPv6 as per the steps above, then you should see the following results when testing from customer-side using this tool:

Routing Loop prevention
If a customer happens to go offline (due to power loss etc), traffic destined for those customers will continue to persist until they time out leading to increased CPU usage. To solve this, we simply route aggregated customer prefixes to blackhole – Because remember in routing, more specific prefixes always win, so should those more specific prefixes go offline, the less specific (aggregated) routes take precedence in which case we are routing to blackhole and hence all pending traffic times out with immediate effect to give us optimal CPU usage.
#RouterOS v7 example#
/ipv4 route
add blackhole comment="Blackhole route for Customer CGNAT pool" disabled=no dst-address=103.176.189.0/25
add blackhole comment="Blackhole route for Customer public pool" disabled=no dst-address=103.176.189.128/25
/ipv6 route
add blackhole comment="Blackhole route for Customer LAN pool" disabled=no dst-address=2405:a140:8::/46
add blackhole comment="Blackhole route for Customer WAN pool" disabled=no dst-address=2405:a140:f:d400::/54#RouterOS v6 example#
/ip route
add type=blackhole comment="Blackhole route for Customer CGNAT pool" disabled=no dst-address=103.176.189.0/25
add type=blackhole comment="Blackhole route for Customer public pool" disabled=no dst-address=103.176.189.128/25
#In RouterOS v6, IPv6 blackhole is not supported#Firewall/Security
Issues
- Blocks inbound ports based on the false logic of “protecting” the customer
- Port blocking does nothing to improve security, it only breaks legitimate traffic such as apps or games that use various methods for VoIP
- Malware can make use of port 443 and that is the reality of modern-day malware anyway
- Net Neutrality Violations
- Such as blocking TCP/UDP traffic destined towards Cloudflare or Google Anycast DNS
- Lacks basic DDoS protection
- Lacks simple bogon filtering
- Lacks basic rules such as dropping invalid traffic on the input chain
- Lacks FastTracking for traffic destined towards your NATted pools
- Connection tracking of customers having a public IPv4 address makes no sense and wastes CPU cycles
- Incorrect ICMPv4/ICMPv6 filtering rules such as rate limiting fragmentation needed and then wonders why customers are facing strange issues with regards to PMTUD
Solutions
- Remove most “port blocking” rules
- Customer Site security should be handled on the customer site such as having proper basic firewalling on their Edge Routers
- I’ve dropped some ports on the RAW table directly
- Avoid Net Neutrality Violation unless otherwise enforced by your local state or central government
- I’ve shared the rule for FastTracking NATted pools
- I’ve shared the rule for reducing connection tracking impact on customers having public IPv4 address
- I have crafted ICMPv4/ICMPv6 manually to drop all deperecated ICMP types while accepting all valid ICMP types
- Source of truth for ICMPv4 deprecated types
- Source of truth for ICMPv6 deprecated types
Below are the generic firewall rules that should be deployed on the BNG to cover basic security grounds.
IPv4 Firewall
#First we take care of address lists#
/ip firewall address-list
#Enter all local subnets/public subnets applicable to your AS for the specific BNG where you've routed pools for use#
#Example I'm using only a /24 public+private pools for this specific BNG#
add address=103.176.189.0/24 comment="Public Pool" list=lan_subnets
add address=192.168.0.0/24 comment="Local interfaces" list=lan_subnets
#The usual CGNAT pool entire range#
add address=100.64.0.0/10 comment="CGNAT Pool" list=lan_subnets
#Here we will enter the public pool used for giving customers public IP addresses directly, this will be used for no-tracking to boost performance of customers having public IPv4 addresses and reduce load on the CPU of the BNG#
add address=103.176.189.0/25 comment="Public Pool" list=public_subnets
###Required for DDoS protection rules###
add list=ddos-attackers
add list=ddos-targets
###Bogon filtering addresses for each of the rules in RAW/Filter###
add address=0.0.0.0/8 comment=RFC6890 list=not_in_internet
add address=172.16.0.0/12 comment=RFC6890 list=not_in_internet
add address=192.168.0.0/16 comment=RFC6890 list=not_in_internet
add address=10.0.0.0/8 comment=RFC6890 list=not_in_internet
add address=169.254.0.0/16 comment=RFC6890 list=not_in_internet
add address=127.0.0.0/8 comment=RFC6890 list=not_in_internet
add address=224.0.0.0/4 comment=Multicast list=not_in_internet
add address=198.18.0.0/15 comment=RFC6890 list=not_in_internet
add address=192.0.0.0/24 comment=RFC6890 list=not_in_internet
add address=192.0.2.0/24 comment=RFC6890 list=not_in_internet
add address=198.51.100.0/24 comment=RFC6890 list=not_in_internet
add address=203.0.113.0/24 comment=RFC6890 list=not_in_internet
add address=100.64.0.0/10 comment=RFC6890 list=not_in_internet
add address=240.0.0.0/4 comment=RFC6890 list=not_in_internet
add address=192.88.99.0/24 comment="6to4 relay Anycast [RFC 3068]" list=not_in_internet
add address=255.255.255.255 comment=RFC6890 list=not_in_internet
add address=127.0.0.0/8 comment="RAW Filtering - RFC6890" list=bad_ipv4
add address=192.0.0.0/24 comment="RAW Filtering - RFC6890" list=bad_ipv4
add address=192.0.2.0/24 comment="RAW Filtering - RFC6890 documentation" list=bad_ipv4
add address=198.51.100.0/24 comment="RAW Filtering - RFC6890 documentation" list=bad_ipv4
add address=203.0.113.0/24 comment="RAW Filtering - RFC6890 documentation" list=bad_ipv4
add address=240.0.0.0/4 comment="RAW Filtering - RFC6890 reserved" list=bad_ipv4
add address=224.0.0.0/4 comment="RAW Filtering - multicast" list=bad_src_ipv4
add address=255.255.255.255 comment="RAW Filtering - RFC6890" list=bad_src_ipv4
add address=0.0.0.0/8 comment="RAW Filtering - RFC6890" list=bad_dst_ipv4
add address=224.0.0.0/4 comment="RAW Filtering - multicast" list=bad_dst_ipv4 disabled=yes
/ip firewall raw
add action=drop chain=prerouting comment="Drop DDoS src and dst address list" dst-address-list=ddos-targets src-address-list=ddos-attackers
add action=drop chain=prerouting comment="drop port 25 to prevent spam" port=25 protocol=tcp
add action=drop chain=prerouting comment="drop port 25 to prevent spam" port=25 protocol=udp
#Required at least in India to reduce call spam/scam#
add action=drop chain=prerouting comment="Drop outgoing SIP to block call centre scammers" port=5060,5061 protocol=tcp
add action=drop chain=prerouting comment="Drop outgoing SIP to block call centre scammers" port=5060,5061 protocol=udp
add action=accept chain=prerouting comment="Enable this rule for transparent mode" disabled=yes
#If you are using DHCP, change this to accept#
add action=drop chain=prerouting comment="defconf: Drop DHCP discover" dst-address=255.255.255.255 dst-port=67 in-interface-list=LAN protocol=udp src-address=0.0.0.0 src-port=68
add action=drop chain=prerouting comment="defconf: drop bad src IPs" src-address-list=bad_ipv4
add action=drop chain=prerouting comment="defconf: drop bad dst IPs" dst-address-list=bad_ipv4
add action=drop chain=prerouting comment="defconf: drop bad src IPs" src-address-list=bad_src_ipv4
add action=drop chain=prerouting comment="defconf: drop bad dst IPs" dst-address-list=bad_dst_ipv4
add action=drop chain=prerouting comment="defconf: drop non global from WAN" in-interface-list=WAN src-address-list=not_in_internet
add action=drop chain=prerouting comment="defconf: drop forward to private ranges from WAN" dst-address-list=not_in_internet in-interface-list=WAN
#Remember to properly enter all subnets in the lan_subnet list for both your AS public IPv4 blocks and CGNAT/local subnets#
add action=drop chain=prerouting comment="defconf: drop local if not from default IP range" in-interface-list=LAN src-address-list=!lan_subnets
add action=drop chain=prerouting comment="defconf: drop bad UDP" port=0 protocol=udp
add action=jump chain=prerouting comment="defconf: jump to TCP chain" jump-target=bad_tcp protocol=tcp
add action=jump chain=prerouting comment="defconf: jump to ICMP chain" jump-target=icmp protocol=icmp
#Rule for reducing connection tracking impact for public IPv4 customers, we no longer exlucde RFC6890 bound packets as the route to blackhole rules takes care of that#
add action=notrack chain=prerouting comment="Reduce load on conn_track" in-interface-list=LAN src-address-list=public_subnets
add action=accept chain=prerouting comment="defconf: accept everything else from LAN" in-interface-list=LAN
add action=accept chain=prerouting comment="defconf: accept everything else from WAN" in-interface-list=WAN
add action=accept chain=prerouting comment="Accept local traffic to self" src-address-type=local
add action=drop chain=prerouting comment="defconf: drop the rest"
add action=drop chain=bad_tcp comment="defconf: TCP port 0 drop" port=0 protocol=tcp
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=!fin,!syn,!rst,!ack
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,syn
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,rst
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,!ack
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,urg
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=syn,rst
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=rst,urg
add action=drop chain=icmp comment="Drop Source Quench (Deprecated)" icmp-options=4 protocol=icmp
add action=drop chain=icmp comment="Drop Alternate Host Address (Deprecated)" icmp-options=6 protocol=icmp
add action=drop chain=icmp comment="Drop Information Request (Deprecated)" icmp-options=15 protocol=icmp
add action=drop chain=icmp comment="Drop Information Reply (Deprecated)" icmp-options=16 protocol=icmp
add action=drop chain=icmp comment="Drop Address Mask Request (Deprecated)" icmp-options=17 protocol=icmp
add action=drop chain=icmp comment="Drop Address Mask Reply (Deprecated)" icmp-options=18 protocol=icmp
add action=drop chain=icmp comment="Drop Traceroute (Deprecated)" icmp-options=30 protocol=icmp
add action=drop chain=icmp comment="Drop Datagram Conversion Error (Deprecated)" icmp-options=31 protocol=icmp
add action=drop chain=icmp comment="Drop Mobile Host Redirect (Deprecated)" icmp-options=32 protocol=icmp
add action=drop chain=icmp comment="Drop IPv6 Where-Are-You (Deprecated)" icmp-options=33 protocol=icmp
add action=drop chain=icmp comment="Drop IPv6 I-Am-Here (Deprecated)" icmp-options=34 protocol=icmp
add action=drop chain=icmp comment="Drop Mobile Registration Request (Deprecated)" icmp-options=35 protocol=icmp
add action=drop chain=icmp comment="Drop Mobile Registration Reply (Deprecated)" icmp-options=36 protocol=icmp
add action=drop chain=icmp comment="Drop Domain Name Request (Deprecated)" icmp-options=37 protocol=icmp
add action=drop chain=icmp comment="Drop Domain Name Reply (Deprecated)" icmp-options=38 protocol=icmp
add action=drop chain=icmp comment="Drop SKIP (Deprecated)" icmp-options=39 protocol=icmp
/ip firewall filter
add action=accept chain=input comment="defconf: accept established,related,untracked" connection-state=established,related,untracked
add action=drop chain=input comment="defconf: drop invalid" connection-state=invalid
add action=accept chain=input comment="defconf: accept ICMP after RAW" protocol=icmp
add action=accept chain=input comment="defconf: accept UDP traceroute" port=33434-33534 protocol=udp
#Example to allow access to router's ports from all interfaces LAN/WAN#
add action=accept chain=input comment="Accept Winbox TCP" dst-port=65000 protocol=tcp
add action=accept chain=input comment="Accept API TCP" dst-port=8728 protocol=tcp
add action=accept chain=input comment="Accept API UDP" dst-port=8728 protocol=udp
add action=accept chain=input comment="Accept SNMP for internal use" dst-port=161 protocol=udp
add action=accept chain=input comment="Accept RADIUS UDP" dst-port=1700,1812,1813 protocol=udp
add action=accept chain=input comment="Accept RADIUS TCP" dst-port=1700,1812,1813 protocol=tcp
#End of example#
add action=drop chain=input comment="defconf: drop all not coming from LAN's interface list/subnets" in-interface-list=!LAN
#PPPoE Clients are excluded as to not bypass queues, if using DHCP excluded src and dst address list of customer pool#
add action=fasttrack-connection chain=forward comment="Rule for NAT Accelaration behaviour (Will reduce CPU usage for NATted traffic)" in-interface=!all-ppp out-interface=!all-ppp
add action=accept chain=forward comment="allow already established connections" connection-state=established,related,untracked
add action=jump chain=forward comment="Jump to DDoS detection" connection-state=new in-interface-list=WAN jump-target=detect-ddos
add action=return chain=detect-ddos dst-limit=50,50,src-and-dst-addresses/10s
add action=add-dst-to-address-list address-list=ddos-targets address-list-timeout=10m chain=detect-ddos
add action=add-src-to-address-list address-list=ddos-attackers address-list-timeout=10m chain=detect-ddos
#This rule should be redudant as we are now routing RFC6890 to blackhole directly and hence I am commenting it out#
#add action=drop chain=forward comment="Drop tries to reach not public addresses from LAN" dst-address-list=not_in_internet in-interface-list=LAN out-interface-list=WAN#IPv6 Firewall
I have now added a rule in the raw table to drop header 0, 43 as per this, now the linked article also suggests dropping header 60, but I decided to not drop header 60 for reasons stated in the re-tweet here – Please note, this only works in ROS v7.4 onwards as there is a bug that was fixed in that version and going forward.
I have now also removed the forward rules completely to improve performance and moved them to the raw table.
/ipv6 firewall address-list
#Enter all the public prefixes that you've routed to this particular BNG#
#We will use this to block spoofed IPv6 coming from customers#
#We will also use this for no-tracking to boost performance of customers having behind the public IPv6 addresses and reduce load on the CPU of the BNG#
#example#
add address=2405:a140:8::/46 comment="CPE-LAN-Pool" list=lan_subnets
add address=2405:a140:c::/54 comment="CPE-WAN-Pool" list=lan_subnets
#Example of any IPv6 you're using on the BNG towards downstream switches/devices/VMs etc#
add address=2405:a140:e::/48 comment="Backbone-Pool" list=lan_subnets
#To prevent breaking link-local#
add address=fe80::/10 comment="Link-local" list=lan_subnets
#Add your BGP peers here, example below#
add address=2400:7000:1::/126 comment="Peering with Transit on VLAN100" list=bgp_peers
#Copy Paste all the following#
add address=::/3 comment="IPv6 invalids" list=not_in_internet
add address=4000::/3 comment="IPv6 invalids" list=not_in_internet
add address=6000::/3 comment="IPv6 invalids" list=not_in_internet
add address=8000::/3 comment="IPv6 invalids" list=not_in_internet
add address=a000::/3 comment="IPv6 invalids" list=not_in_internet
add address=c000::/3 comment="IPv6 invalids" list=not_in_internet
add address=e000::/4 comment="IPv6 invalids" list=not_in_internet
add address=f000::/5 comment="IPv6 invalids" list=not_in_internet
add address=f800::/6 comment="IPv6 invalids" list=not_in_internet
add address=fc00::/7 comment="IPv6 invalids" list=not_in_internet
add address=fe00::/9 comment="IPv6 invalids" list=not_in_internet
add address=fec0::/10 comment="IPv6 invalids" list=not_in_internet
add address=2001::/23 comment="IPv6 invalids" list=not_in_internet
add address=2001:2::/48 comment="IPv6 invalids" list=not_in_internet
add address=2001:10::/28 comment="IPv6 invalids" list=not_in_internet
add address=2001:db8::/32 comment="IPv6 invalids" list=not_in_internet
add address=2002::/16 comment="IPv6 invalids" list=not_in_internet
add address=3ffe::/16 comment="IPv6 invalids" list=not_in_internet
#We will use this to eliminate the need for stateful firewalling on IPv6 to catch spoofed traffic in the raw table instead of forward chain#
add address=2000::/3 list="global_unicast_prefix(es)"
add address=fe80::/10 list=allowed
add address=ff02::/16 comment="multicast" list=allowed
add address=fe80::/10 comment="defconf: RFC6890 Linked-Scoped Unicast" list=no_forward_ipv6
add address=ff00::/8 comment="defconf: multicast" list=no_forward_ipv6
add address=::1/128 comment="defconf: lo" list=bad_ipv6
add address=::ffff:0:0/96 comment="defconf: ipv4-mapped" list=bad_ipv6
add address=::/96 comment="defconf: ipv4 compat" list=bad_ipv6
add address=2001:db8::/32 comment="defconf: documentation" list=bad_ipv6
add address=2001:10::/28 comment="defconf: ORCHID" list=bad_ipv6
add address=2001::/23 comment="defconf: RFC6890" list=bad_ipv6
add address=::/128 comment="defconf: unspecified" list=bad_dst_ipv6
add address=::/128 comment="RAW Filtering" list=bad_src_ipv6
add address=ff00::/8 comment="RAW Filtering" list=bad_src_ipv6
/ipv6 firewall raw
#New rule to drop deprecated header type 0 & 40#
#Works only on ROS v7.4 onwards#
add action=drop chain=prerouting comment="Drop packets with extension header types 0, 43" headers=hop,route:contains
add action=accept chain=prerouting comment="defconf: RFC4291, section 2.7.1" dst-address=ff02::1:ff00:0/104 icmp-options=135:0-255 protocol=icmpv6 src-address=::/128
#Migrated this rule from the foward chain to make it more CPU efficient#
add action=drop chain=prerouting comment="defconf: rfc4890 drop hop-limit=1" hop-limit=equal:1 in-interface-list=!LAN protocol=icmpv6
add action=drop chain=prerouting comment="drop port 25 to prevent spam" port=25 protocol=tcp
add action=drop chain=prerouting comment="drop port 25 to prevent spam" port=25 protocol=udp
#This is required for traffic whereby the SRC may be Link-local and the DST is GUA for BGP peers particuarly in IXPs#
add action=accept chain=prerouting comment="Accept all ICMPv6 traffic from BGP peers (Required for LL<>GUA packets)" icmp-options=!154:4-5 in-interface-list=WAN protocol=icmpv6 src-address-list=bgp_peers
add action=drop chain=prerouting comment="Drop invalids from WAN" dst-address-list="global_unicast_prefix(es)" in-interface-list=WAN src-address-list=not_in_internet
add action=drop chain=prerouting comment="Drop forwarded invalids from WAN" dst-address-list=not_in_internet in-interface-list=WAN src-address-list="global_unicast_prefix(es)"
add action=drop chain=prerouting comment="Drop invalids from LAN" dst-address-list="global_unicast_prefix(es)" in-interface-list=LAN src-address-list=not_in_internet
add action=drop chain=prerouting comment="Drop forwarded invalids from LAN" dst-address-list=not_in_internet in-interface-list=LAN src-address-list=lan_subnets
#This rule replaces the need for forward chain rule for doing the same thing#
add action=drop chain=prerouting comment="Drop spoofed traffic from LAN going towards Global Unicast" dst-address-list="global_unicast_prefix(es)" in-interface-list=LAN src-address-list=!lan_subnets
add action=accept chain=prerouting comment="defconf: enable for transparent firewall" disabled=yes
add action=drop chain=prerouting comment="defconf: drop bogon IP's" src-address-list=bad_ipv6
add action=drop chain=prerouting comment="defconf: drop bogon IP's" dst-address-list=bad_ipv6
add action=drop chain=prerouting comment="defconf: drop packets with bad src ipv6" src-address-list=bad_src_ipv6
add action=drop chain=prerouting comment="defconf: drop packets with bad dst ipv6" dst-address-list=bad_dst_ipv6
add action=accept chain=prerouting comment="defconf: accept local multicast scope" dst-address=ff02::/16
add action=drop chain=prerouting comment="defconf: drop other multicast destinations" dst-address=ff00::/8
add action=drop chain=prerouting comment="defconf: drop bad UDP" port=0 protocol=udp
add action=drop chain=prerouting comment="defconf: drop bad TCP" port=0 protocol=tcp
add action=jump chain=prerouting comment="defconf: jump to ICMP chain" jump-target=icmpv6 protocol=icmpv6
#Since all filtering for LAN is done in RAW, we do not need to have stateful tracking for LAN, and hence we are notracking all LAN originating/bound traffic after filtering#
add action=notrack chain=output comment="Reduce load on conn_track" in-interface-list=LAN
add action=notrack chain=output comment="Reduce load on conn_track" out-interface-list=LAN
add action=notrack chain=prerouting comment="Reduce load on conn_track" in-interface-list=LAN
add action=notrack chain=prerouting comment="Reduce load on conn_track" dst-address-list=lan_subnets in-interface-list=WAN
add action=accept chain=prerouting comment="defconf: accept everything else from LAN" in-interface-list=LAN
add action=accept chain=prerouting comment="defconf: accept everything else from WAN" in-interface-list=WAN
add action=accept chain=prerouting comment="Accept local traffic to self" src-address-type=local
add action=drop chain=prerouting comment="defconf: drop the rest"
add action=drop chain=icmpv6 comment="Drop FMIPv6 HI + FMIPv6 HAck - Deprecated (RFC5568)" icmp-options=154:4-5 protocol=icmpv6
/ipv6 firewall filter
add action=accept chain=input comment="defconf: accept established,related,untracked" connection-state=established,related,untracked
add action=drop chain=input comment="defconf: drop invalid" connection-state=invalid
add action=accept chain=input comment="defconf: accept ICMPv6" protocol=icmpv6
add action=accept chain=input comment="defconf: accept UDP traceroute" port=33434-33534 protocol=udp
add action=accept chain=input comment="defconf: accept DHCPv6-Client prefix delegation." dst-port=546 protocol=udp src-address=fe80::/10
#Example to allow access to router's ports from all interfaces LAN/WAN#
add action=accept chain=input comment="Accept Winbox TCP" dst-port=65000 protocol=tcp
add action=accept chain=input comment="Accept API TCP" dst-port=8728 protocol=tcp
add action=accept chain=input comment="Accept API UDP" dst-port=8728 protocol=udp
add action=accept chain=input comment="Accept SNMP for internal use" dst-port=161 protocol=udp
add action=accept chain=input comment="Accept RADIUS UDP" dst-port=1700,1812,1813 protocol=udp
add action=accept chain=input comment="Accept RADIUS TCP" dst-port=1700,1812,1813 protocol=tcp
#End of example#
add action=accept chain=input comment="allow allowed addresses" src-address-list=allowed
add action=drop chain=input comment="defconf: drop everything else not coming from LAN" in-interface-list=!LAN
#All forward rules have been migrated to the RAW table for BNGs, so better performance and no stateful tracking required for customers#For Edge Router
The purpose of the Edge router is to route as fast as possible. So, with that in mind, along with the basic general changes I’ve mentioned at the beginning of this article, the following should also be kept in mind:
- No NAT
- No connection tracking aka stateful firewalling (filter table on the firewall section)
- If you enable stateful firewalling on the edge, the router will die in case of DDoS attacks or even just heavy traffic in general
- No fancy “features” (like Hotspot, PPPoE)
- Use your BNG routers for any customer delegation that is required
BGP Optimisation
This is a work in progress section and at this point in time, I am writing based on my experience with Indian ISPs, so if you’re in the EU/US or other locations, you’re probably already implementing the following:
Please note on RouterOS v7, you need to properly configure BGP affinity to avoid CPU issues.
BGP Timers
Based on Huawei documentation here and here, I personally tested the following configuration and observed that BGP negotiation time and stability (during occasional link flaps/packet loss) improved significantly, so I would recommend network operators to set the same timers globally on their networks (for both eBGP and iBGP) – Keepalive time to 20s, Holdtime to 60s.
/routing bgp template
set default as=149794 disabled=no hold-time=1m keepalive-time=20s
Preferably convince your peers to do the same config on their end as well at least for the individual BGP sessions that are between you and them.
Traffic Engineering and loop prevention
- Always route your aggregated prefixes [Like say you have a /24 or /22 (IPv4) or /32 or /36 (IPv6)] to blackhole for IPv4+IPv6 to prevent layer 3 looping and stop disabling synchronisation on RouterOS v6, it is anyways mandatory on RouterOS v7 to either route to blackhole or have the prefix assigned to an interface
- This will also reduce CPU usage whenever downstream routers/users/switches go offline and incomplete traffic from remote hosts/networks keeps trying to establish a connection and since it gets routed to blackhole it will immediately timeout and save resources.
- In other words, there’s no sense in doing things that increase CPU usage (not routing to blackhole)
- And there is no sense in avoiding loop prevention mechanisms
- Example config on my own network (AS149794) on RouterOS v7
/ip route
add blackhole comment="Blackhole route" disabled=no dst-address=103.176.189.0/24/ipv6 route
add blackhole comment="Blackhole Route" disabled=no dst-address=2400:7060::/32
add blackhole comment="Blackhole Route" disabled=no dst-address=2400:7060::/48
- This will also reduce CPU usage whenever downstream routers/users/switches go offline and incomplete traffic from remote hosts/networks keeps trying to establish a connection and since it gets routed to blackhole it will immediately timeout and save resources.
- If you have multi-homing transit
- Always at the very least, request for partial routing table from all the upstream providers you’re connected to. If the router can handle full tables from the upstreams, go for it!
- This will ensure your router has the best paths to choose from
- Stop going with the strange concept of taking only default routes from the upstreams and creating asymmetric routing conditions where outgoing traffic is going via Transit A and incoming traffic is coming in via Transit B.
- Always advertise all your IP pools to all transit providers to help minimise asymmetric routing which in turn leads to high latency and possibly packet loss in rare cases
- If you need traffic engineering, you can consider BGP based load balancing or local preferences with some automation like Pathvector
- Always at the very least, request for partial routing table from all the upstream providers you’re connected to. If the router can handle full tables from the upstreams, go for it!
- If you have a single homing setup
- Still request for partial table/full table whichever fits your router’s specs in order to futureproof in case you plan to go multi-home
Filtering & Security
We only need to do broadly two things for filtering and security:
- Implement MANRS throughout your network (and business)
- Use the RAW table to drop remaining bogon/rubbish traffic similar to the one used on the BNG and you can also use it for ACL if you need that
- CPU usage stays minimal when using the RAW table
- Absolutely nothing on the filter table i.e. no stateful firewalling
- The only exception here is we can use FastTrack for untracked traffic i.e. stateless traffic to improve IPv4 routing performance
IPv4 Firewall
#Disable conn_track for using FastTrack statelessly#
/ip firewall connection tracking
set enabled=no
/ip firewall address-list
#Enter all local subnets/public subnets applicable to your AS, use the full CIDR notation of the public IPv4 block assigned to you to avoid missing anything out, please avoid something like /30#
add address=103.176.189.0/24 comment="LAN subnets" list=lan_subnets
add address=192.168.0.0/24 comment="LAN subnets" list=lan_subnets
add address=0.0.0.0/8 comment=RFC6890 list=not_in_internet
add address=172.16.0.0/12 comment=RFC6890 list=not_in_internet
add address=192.168.0.0/16 comment=RFC6890 list=not_in_internet
add address=10.0.0.0/8 comment=RFC6890 list=not_in_internet
add address=169.254.0.0/16 comment=RFC6890 list=not_in_internet
add address=127.0.0.0/8 comment=RFC6890 list=not_in_internet
add address=224.0.0.0/4 comment=Multicast list=not_in_internet
add address=198.18.0.0/15 comment=RFC6890 list=not_in_internet
add address=192.0.0.0/24 comment=RFC6890 list=not_in_internet
add address=192.0.2.0/24 comment=RFC6890 list=not_in_internet
add address=198.51.100.0/24 comment=RFC6890 list=not_in_internet
add address=203.0.113.0/24 comment=RFC6890 list=not_in_internet
add address=100.64.0.0/10 comment=RFC6890 list=not_in_internet
add address=240.0.0.0/4 comment=RFC6890 list=not_in_internet
add address=192.88.99.0/24 comment="6to4 relay Anycast [RFC 3068]" list=not_in_internet
add address=255.255.255.255 comment=RFC6890 list=not_in_internet
add address=127.0.0.0/8 comment="RAW Filtering - RFC6890" list=bad_ipv4
add address=192.0.0.0/24 comment="RAW Filtering - RFC6890" list=bad_ipv4
add address=192.0.2.0/24 comment="RAW Filtering - RFC6890 documentation" list=bad_ipv4
add address=198.51.100.0/24 comment="RAW Filtering - RFC6890 documentation" list=bad_ipv4
add address=203.0.113.0/24 comment="RAW Filtering - RFC6890 documentation" list=bad_ipv4
add address=240.0.0.0/4 comment="RAW Filtering - RFC6890 reserved" list=bad_ipv4
add address=224.0.0.0/4 comment="RAW Filtering - multicast" list=bad_src_ipv4
add address=255.255.255.255 comment="RAW Filtering - RFC6890" list=bad_src_ipv4
add address=0.0.0.0/8 comment="RAW Filtering - RFC6890" list=bad_dst_ipv4
add address=224.0.0.0/4 comment="RAW Filtering - multicast" list=bad_dst_ipv4 disabled=yes
/ip firewall raw
add action=accept chain=prerouting comment="Enable this rule for transparent mode" disabled=yes
#If you are using DHCP, change this to accept#
add action=drop chain=prerouting comment="defconf: Drop DHCP discover on LAN" dst-address=255.255.255.255 dst-port=67 in-interface-list=LAN protocol=udp src-address=0.0.0.0 src-port=68
add action=drop chain=prerouting comment="defconf: drop bad src IPs" src-address-list=bad_ipv4
add action=drop chain=prerouting comment="defconf: drop bad dst IPs" dst-address-list=bad_ipv4
add action=drop chain=prerouting comment="defconf: drop bad src IPs" src-address-list=bad_src_ipv4
add action=drop chain=prerouting comment="defconf: drop bad dst IPs" dst-address-list=bad_dst_ipv4
add action=drop chain=prerouting comment="defconf: drop non global from WAN" in-interface-list=WAN src-address-list=not_in_internet
add action=drop chain=prerouting comment="defconf: drop forward to private ranges from WAN" dst-address-list=not_in_internet in-interface-list=WAN
#Remember that lan_subnets here should only include your public ranges not CGNAT#
add action=drop chain=prerouting comment="defconf: drop local if not from default IP range" in-interface-list=LAN src-address-list=!lan_subnets
add action=drop chain=prerouting comment="defconf: drop bad UDP" port=0 protocol=udp
add action=jump chain=prerouting comment="defconf: jump to TCP chain" jump-target=bad_tcp protocol=tcp
add action=jump chain=prerouting comment="defconf: jump to ICMP chain" jump-target=icmp protocol=icmp
add action=accept chain=prerouting comment="defconf: accept UDP traceroute" dst-address-type=local port=33434-33534 protocol=udp
add action=accept chain=prerouting comment="defconf: accept everything else from LAN" in-interface-list=LAN
add action=accept chain=prerouting comment="defconf: accept everything else from WAN" in-interface-list=WAN
add action=accept chain=prerouting comment="Accept local traffic to self" src-address-type=local
add action=drop chain=prerouting comment="defconf: drop the rest"
add action=drop chain=bad_tcp comment="defconf: TCP port 0 drop" port=0 protocol=tcp
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=!fin,!syn,!rst,!ack
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,syn
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,rst
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,!ack
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=fin,urg
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=syn,rst
add action=drop chain=bad_tcp comment="defconf: TCP flag filter" protocol=tcp tcp-flags=rst,urg
add action=drop chain=icmp comment="Drop Source Quench (Deprecated)" icmp-options=4 protocol=icmp
add action=drop chain=icmp comment="Drop Alternate Host Address (Deprecated)" icmp-options=6 protocol=icmp
add action=drop chain=icmp comment="Drop Information Request (Deprecated)" icmp-options=15 protocol=icmp
add action=drop chain=icmp comment="Drop Information Reply (Deprecated)" icmp-options=16 protocol=icmp
add action=drop chain=icmp comment="Drop Address Mask Request (Deprecated)" icmp-options=17 protocol=icmp
add action=drop chain=icmp comment="Drop Address Mask Reply (Deprecated)" icmp-options=18 protocol=icmp
add action=drop chain=icmp comment="Drop Traceroute (Deprecated)" icmp-options=30 protocol=icmp
add action=drop chain=icmp comment="Drop Datagram Conversion Error (Deprecated)" icmp-options=31 protocol=icmp
add action=drop chain=icmp comment="Drop Mobile Host Redirect (Deprecated)" icmp-options=32 protocol=icmp
add action=drop chain=icmp comment="Drop IPv6 Where-Are-You (Deprecated)" icmp-options=33 protocol=icmp
add action=drop chain=icmp comment="Drop IPv6 I-Am-Here (Deprecated)" icmp-options=34 protocol=icmp
add action=drop chain=icmp comment="Drop Mobile Registration Request (Deprecated)" icmp-options=35 protocol=icmp
add action=drop chain=icmp comment="Drop Mobile Registration Reply (Deprecated)" icmp-options=36 protocol=icmp
add action=drop chain=icmp comment="Drop Domain Name Request (Deprecated)" icmp-options=37 protocol=icmp
add action=drop chain=icmp comment="Drop Domain Name Reply (Deprecated)" icmp-options=38 protocol=icmp
add action=drop chain=icmp comment="Drop SKIP (Deprecated)" icmp-options=39 protocol=icmp
#Filter rules for FastTracking stateless traffic#
/ip firewall mangle
add action=fasttrack-connection chain=prerouting
add action=fasttrack-connection chain=outputIPv6 Firewall
/ipv6 firewall address-list
#Enter the aggregated public prefixes originating from your AS that you use along with link-local fe80::/10#
#example#
add address=2405:a140::/32 comment="AS Prefix" list=lan_subnets
add address=fe80::/10 comment="Link-local" list=lan_subnets
#Add your BGP peers here, example below#
add address=2400:7000:1::/126 comment="Peering with Transit on VLAN100" list=bgp_peers
#Copy Paste all the following#
add address=::/3 comment="IPv6 invalids" list=not_in_internet
add address=4000::/3 comment="IPv6 invalids" list=not_in_internet
add address=6000::/3 comment="IPv6 invalids" list=not_in_internet
add address=8000::/3 comment="IPv6 invalids" list=not_in_internet
add address=a000::/3 comment="IPv6 invalids" list=not_in_internet
add address=c000::/3 comment="IPv6 invalids" list=not_in_internet
add address=e000::/4 comment="IPv6 invalids" list=not_in_internet
add address=f000::/5 comment="IPv6 invalids" list=not_in_internet
add address=f800::/6 comment="IPv6 invalids" list=not_in_internet
add address=fc00::/7 comment="IPv6 invalids" list=not_in_internet
add address=fe00::/9 comment="IPv6 invalids" list=not_in_internet
add address=fec0::/10 comment="IPv6 invalids" list=not_in_internet
add address=2001::/23 comment="IPv6 invalids" list=not_in_internet
add address=2001:2::/48 comment="IPv6 invalids" list=not_in_internet
add address=2001:10::/28 comment="IPv6 invalids" list=not_in_internet
add address=2001:db8::/32 comment="IPv6 invalids" list=not_in_internet
add address=2002::/16 comment="IPv6 invalids" list=not_in_internet
add address=3ffe::/16 comment="IPv6 invalids" list=not_in_internet
add address=2000::/3 list="global_unicast_prefix(es)"
add address=fe80::/10 list=allowed
add address=ff02::/16 comment="multicast" list=allowed
add address=fe80::/10 comment="defconf: RFC6890 Linked-Scoped Unicast" list=no_forward_ipv6
add address=ff00::/8 comment="defconf: multicast" list=no_forward_ipv6
add address=::1/128 comment="defconf: lo" list=bad_ipv6
add address=::ffff:0:0/96 comment="defconf: ipv4-mapped" list=bad_ipv6
add address=::/96 comment="defconf: ipv4 compat" list=bad_ipv6
add address=2001:db8::/32 comment="defconf: documentation" list=bad_ipv6
add address=2001:10::/28 comment="defconf: ORCHID" list=bad_ipv6
add address=2001::/23 comment="defconf: RFC6890" list=bad_ipv6
add address=::/128 comment="defconf: unspecified" list=bad_dst_ipv6
add address=::/128 comment="RAW Filtering" list=bad_src_ipv6
add address=ff00::/8 comment="RAW Filtering" list=bad_src_ipv6
/ipv6 firewall raw
#New rule to drop deprecated header type 0 & 40#
#Works only on ROS v7.4 onwards#
add action=drop chain=prerouting comment="Drop packets with extension header types 0, 43 at network border" headers=hop,route:contains
add action=accept chain=prerouting comment="defconf: RFC4291, section 2.7.1" dst-address=ff02::1:ff00:0/104 icmp-options=135:0-255 protocol=icmpv6 src-address=::/128
#Migrated this rule from the foward chain in BNG to drop these packets on the network edge#
add action=drop chain=prerouting comment="defconf: rfc4890 drop hop-limit=1" hop-limit=equal:1 in-interface-list=!LAN protocol=icmpv6
add action=drop chain=prerouting comment="drop port 25 to prevent spam" port=25 protocol=tcp
add action=drop chain=prerouting comment="drop port 25 to prevent spam" port=25 protocol=udp
#This is required for traffic whereby the SRC may be Link-local and the DST is GUA for BGP peers particuarly in IXPs#
add action=accept chain=prerouting comment="Accept all ICMPv6 traffic from BGP peers (Required for LL<>GUA packets)" icmp-options=!154:4-5 in-interface-list=WAN protocol=icmpv6 src-address-list=bgp_peers
add action=drop chain=prerouting comment="Drop invalids from WAN" dst-address-list="global_unicast_prefix(es)" in-interface-list=WAN src-address-list=not_in_internet
add action=drop chain=prerouting comment="Drop forwarded invalids from WAN" dst-address-list=not_in_internet in-interface-list=WAN src-address-list="global_unicast_prefix(es)"
add action=drop chain=prerouting comment="Drop invalids from LAN" dst-address-list="global_unicast_prefix(es)" in-interface-list=LAN src-address-list=not_in_internet
add action=drop chain=prerouting comment="Drop forwarded invalids from LAN" dst-address-list=not_in_internet in-interface-list=LAN src-address-list=lan_subnets
add action=accept chain=prerouting comment="defconf: enable for transparent firewall" disabled=yes
#Drop anything from your network going towards the public internet if source addresses does not match your allocated pools#
add action=drop chain=prerouting comment="Drop spoofed traffic from LAN going towards Global Unicast" dst-address-list="global_unicast_prefix(es)" in-interface-list=LAN src-address-list=!lan_subnets
add action=drop chain=prerouting comment="defconf: drop bogon IP's" src-address-list=bad_ipv6
add action=drop chain=prerouting comment="defconf: drop bogon IP's" dst-address-list=bad_ipv6
add action=drop chain=prerouting comment="defconf: drop packets with bad src ipv6" src-address-list=bad_src_ipv6
add action=drop chain=prerouting comment="defconf: drop packets with bad dst ipv6" dst-address-list=bad_dst_ipv6
add action=accept chain=prerouting comment="defconf: accept local multicast scope" dst-address=ff02::/16
add action=drop chain=prerouting comment="defconf: drop other multicast destinations" dst-address=ff00::/8
add action=drop chain=prerouting comment="defconf: drop bad UDP" port=0 protocol=udp
add action=drop chain=prerouting comment="defconf: drop bad TCP" port=0 protocol=tcp
add action=accept chain=prerouting comment="defconf: accept UDP traceroute" dst-address-type=local port=33434-33534 protocol=udp
add action=jump chain=prerouting comment="defconf: jump to ICMP chain" jump-target=icmpv6 protocol=icmpv6
add action=accept chain=prerouting comment="defconf: accept everything else from LAN" in-interface-list=LAN
add action=accept chain=prerouting comment="defconf: accept everything else from WAN" in-interface-list=WAN
add action=accept chain=prerouting comment="Accept local traffic to self" src-address-type=local
add action=drop chain=prerouting comment="defconf: drop the rest"
add action=drop chain=icmpv6 comment="Drop FMIPv6 HI + FMIPv6 HAck - Deprecated (RFC5568)" icmp-options=154:4-5 protocol=icmpv6Firewall Explanation
I will keep this concise as stated earlier I suggest you study and understand how iptables function in general and study the packet flow to know what rule does what: With that being said, I will break it down into simpler points
- I used this and this as the source for building the base for the firewall
- MikroTik has ensured to conform to various RFCs and taken the efforts to not break any legitimate protocol/traffic
- IPv6 firewall rules are trickier and more complex, but rest assured that the rules in this article do not break any protocol/standard nor do they impact customer’s end-to-end reachability
- We are dropping spoofed traffic
- The RAW rules drop anything coming from WAN that’s spoofed (RFC 6890 addresses)
- The RAW rules drop anything coming from LAN that does not match your public prefixes/internal subnets (aka lan_subnets address list), meaning any spoofing traffic is dropped from exiting your network
- Here’s an APNIC blog post detailing more on this subject
- Next, we are dropping bad traffic such as TCP/UDP port 0 or bad TCP flags
- The filter rules are pretty self-explanatory
Strange Anomalies
These are some strange behaviours that I could not explain. If you have further information, please reach out to me.
- NAT Leak
- For example, let’s say we CGNAT 100.64.0.0/24 to customers with 103.176.189.0/25. Now, it’s common sense that anything WAN bound will have a source IP belonging to the /25 on the other end of the NAT. But nope, this isn’t always the case. What I have observed is, sometimes (meaning all the time if you have thousands of customers), the source IP would be the CGNAT subnet and the destination IP would be public, hence it “escapes” from the NAT engine.
- This behaviour is NOT exclusive to MikroTik. I have observed the same thing on Ubuntu 20.04/Debian based distros, where the source IP is the NAT subnet and it escapes to the WAN interface with the destination IP being real-live public IPs
- Solution: We just drop anything coming from the BNG that’s not public using the Edge Router, this is already taken care of in my configuration above, you just need to follow the instructions
- I have been unable to find documentation or bug reports on this behaviour
- Netmap vs Src Nat
- Publicly available documentation suggests simple definitions for both
Src NAT = 1:Many binding
Netmap = 1:1 binding- But for whatever reason, when using src NAT as the action for a public prefix, it keeps on changing the “NATted” public IP and hence the source IP on the WAN for the customers. This results in traffic breaking or triggering DDoS protection on sites like Cloudflare protected ones
- And for whatever reason, even though Netmap is meant for 1:1, it works for 1:Many bindings and it does not result in the constant changing of source IP for the customers
- I have not found any technical information on why these behaviours occur or why netmap even works in the first place for 1:Many bindings
- Publicly available documentation suggests simple definitions for both
Such a detailed address of the issues that is so important while in implementation…
Thanks
Hi Daryll, well done!!!, it was the key for fix a problem I had been triyng to fix in a customer (ISP).
I would like you could read my problem: https://forum.mikrotik.com/viewtopic.php?f=2&t=176378
I repeat, That problem its fixed now, thanks of you!.
I used the following command of your article (with a little modifications):
/ip firewall nat
add action=netmap chain=srcnat comment=”NETMAP PPPoE” out-interface=sfp1-Internet src-address-list=Clientes_NAT to-addresses=PUBLIC/32
I don’t understand what is the difference using “srcnat action masquerade” (witch it wasn’t working) and using “Netmap” (witch for shure it runned perfectly fine at the first moment that I put it). I want to learn/understand why this way is working.
Thanks a lot.
Regards from Argentina
I hope this helps you.
Just note that you are missing parameters in your rule, re-check from my article again.
thx Daryll for this blog, it gonna help me with https://forum.mikrotik.com/viewtopic.php?f=2&t=176759&p=866896#p866896
the reason I’m writing is, that I was told that there are possibilities why an IP can be leaked.
Have a look here at could be that we get an answer to a shared question:
Strange Anomalies –> NAT Leak –> https://forum.mikrotik.com/viewtopic.php?f=2&t=177210&p=870126
For the NAT Leak issue, it mostly looks like speculation on that thread in my opinion. No factual/documented information yet, but I’ll keep an eye on it.
unfortunately, that is the case. When the conclusion are a bit more solid I will email support anyway, may they resolve the mystery
Good morning,
could you share what was updated?
thx 🙂
Well, it depends on when you last visited the site? 🙂
Added:
QoS/Bandwidth management suggestion, IPv6 for BNGs with PPPoE, IPv6 tweaks, IPv6 firewalling for both Edge and BNGs, slightly tweaked the IPv4 firewall rules for both, MTU section is finalised, CGNAT section is finalised. That’s about it I think.
that is true :), it was end if July.
I received an notification from WordPress yesterday that a new post was added.
As there was not any, I guessed it was due to the update of the blog.
I don’t know if notification are sent as well if the blog is updated
There is a new post:
http://daryllswer.com/the-human-side-of-isps/
First off, thank you so much for this! Im currently in the middle of a major network upgrade for our ISP and this post has been absolute gold. Ive learned a ton.
Anyways, I have a quick question about the Firewall DDoS protection jump chain.
add action=jump chain=forward comment=”Jump to DDoS detection” connection-state=new in-interface-list=WAN jump-target=detect-ddos
Why is it only on the forward chain and not the input chain as well? The Mikrotik help page has it this way as well (forward chain only) but Ive been running it on the input and forward chains for a while now. I havent had any issues but im curious if there is there any particular reason why you do not have DDoS on input chain?
Input chain means the router itself:
1. There’s nothing it will do when the DDoS traffic is hitting the router, the link will still choke. You need to have proper DDoS mitigation from/with your upstream
2. I’ve tested it for fun on the input chain and it ended up breaking traffic that’s destined towards the router itself such as DNS lookups.
Hence there’s no point in applying those rules in the input chain. They are in the forward chain in order to protect your downstream users.
Hey Daryll, got another question for you.
I noticed that when disabling connection tracking on the Edge Router, the Mikrotik puts an auto RAW rule with action=no track for the prerouting and output at the very bottom of the RAW rule table.
But with the prerouting action = no track being at the bottom, no packets are hitting that rule. So I assume the firewall is still tracking connections as they pass the RAW rules above it.
The Mikrotik will not allow me to drag that rule to the top, but I can drag my other RAW rules below it and I can then see packets hitting that prerouting rule. But when I reboot the router, it places those rules back at the bottom again?
Are you seeing the same thing? Or are your prerouting action= no track rules stay at the top? Im on long-term v6.48.6 btw
I believe MikroTik does conn_track disable by the means of no tracking via the raw table, but more likely than not, what you’re seeing is a bug. As long as the packets are hitting your other raw rules, it isn’t an issue. Check the connection tracking tab, if there’s nothing there, then we know for sure, connection tracking is disabled. And as long as you’re seeing the expected routing performance throughput, we can also safely assume connection tracking was disabled.
So I just tried deleting all the rules and making sure I disable the connection tracking before input RAW rule set again. The Mikrotik still places those no track rules at the end of the rule set after reboot again. Is this a bug or is this a misunderstanding on my part?
I just tested it out on my personal router running v7.1.1 as I wrote this, I’m unable to replicate what you saw after rebooting. I’m 100% sure it’s a bug.
I’d suggest a netinstall once with the latest long-term and ensure /system routerboard firmware is also running the latest long-term (rebooted twice for it to work).
No I definitely have connections there. The reason I rebooted my router was to see if those connections would disappear after moving the rules. Ill submit bug to Mikrotik support Thanks for the clarification
Yea, its a 6.48.6 bug. Im seeing it on 4 of my CCR1036’s and I duplicated it on my home RB4011. Ill be submitting this to support. Thanks again!
That’s MikroTik for ya 😉
(Full of bugs)
Question: If you disable connection tracking, is there any real difference between a Filter rule vs a RAW rule? I get wanting to keep all FW rules to an absolute minimum but if connection tracking is disabled, then from a performance perspective, it would be the same other than now a filter rule gives you more flexibilty in terms of being able to block at the input or forward chain where as a RAW rule is more generic.
For example, if I still wanted to keep an ACL whitelist for input chain to router for security reasons, my rule would look like this.
/ip firewall filter
add action=drop chain=input comment=”Drop ALL except from TRUSTED” src-address-list=!TRUSTED
First, a caveat, the filter table cannot work without connection tracking, it is by definition stateful and hence needs state tracking.
Edge/Border routers are not supposed to have connection tracking enabled. They are routers meant to route and forward traffic inter-AS as seamlessly as possible and not filter nor act as a firewall. The most we can do on the edge of a network is drop bogon traffic as we know for a fact, they should never enter a network, to begin with, and serve no functional purpose. (I will update the IPv6 raw table to drop some headers on the edge as per 2022 practices that serve have no functional purpose as well)
If you enable conn_track on the edge, the performance impact will be visible downstream to the customers and your eBGP router will just randomly reboot once customers saturate the conn_track table. On top of that, you’d be creating a butterfly effect of ugly NAT keep-alive or just keep-alive traffic to now choke not only the BNGs but also the eBGP routers and impact performance even further.
The raw table gives us the ability to still firewall without the performance impact of stateful tracking. In other words, it’s stateless firewalling.
So if you want to ACL access to the router, you can still use RAW like:
/ip firewall raw
add action=drop chain=prerouting comment=”Drop ALL except from TRUSTED” src-address-list=!TRUSTED dst-address-list=[Your list containing IPs of the interface/router etc]
However, although this is the most optimal option available on MikroTik, it is not the currently accepted standards or best practices, as the world moves to eBPF/XDP (while MikroTik is playing catch-up for the last 10 years):
https://blog.cloudflare.com/how-to-drop-10-million-packets/
You can also find in the above article some data that shows no-track (conn_track disabled) outperforms conn_track enabled.
At the end of the day, if a high-performance Edge/Border router is what a network needs, it’s certainly something MikroTik cannot deliver at this point in time.
Under your IPv6 raw rules, is there supposed to be a !lan_subnets drop rule for Edge Router? I dont see it.
Create it if I missed it on the rules. Drop anything that’s not the public prefixes allocated to your network.
Edit: fe80::/10 should also be a member of lan_subnets to avoid breaking link-local.
Thats the answer I was looking for. Thank you!
I’ve tweaked the !lan raw IPv6 rules. Now it makes more sense and removes the need for forward chain rule on BNG and simplifies it for the edge router.
However, should IANA ever make changes to the IPv6 blocks, you’d need to update this manually.
/ip fi rawadd action=drop chain=prerouting comment="Drop spoofed traffic from LAN going towards Global Unicast" dst-address=2000::/3 in-interface-list=LAN src-address-list=!lan_subnets
Ahhhh….so to reinforce your point….and regarding that earlier bug we found, I noticed that those FW Raw ‘no track’ rules disappear inside the Raw table when I disabled my lone FW input rule with connection tracking disabled. All makes sense now.
I see you have updates but its difficult to know what they are and where. Would it be possible to give some kind of changelog and/or highlight improvements/changes you have made?
I would need a systematic approach or maybe some WP plugin that can do the job. Do you know any? Writing a manual changelog for documentation this big is too much of a tedious task really.
can you suggest a budget RADIUS sever other than Radius Manager
You can ask other operators in the public group.
Yea, I hear ya, just throwing the idea out there. The bold explanations do help quite a bit. The BGP Optimization section is a nice addition. I learn more each time I go through it.
Help spread the word, and share this article with other network operators and engineers, it benefits the ecosystem if everyone deployed best practices end-to-end.
If you know somebody who can convert this guide into a Cisco and Juniper equivalent, that’d be great too.
Absolutely! Myself and another poster (who introduced me to this blog) on r/mikrotik on Reddit as well as the Mikrotik forums take every chance we get to share this with others. Keep up the excellent work. Its very much appreciated!
BTW, you have some minor typos you might wanna fix when you get a chance:
The address list “global_unicast_prefix(es)” in your IPv6 raw rule doesnt paste properly in terminal
add action=drop chain=prerouting comment=”Drop invalids from WAN” dst-address-list=global_unicast_prefix(es) in-interface-list=WAN src-address-list=not_in_internet
Had to drop the parenthesis inside the address list name to get it to paste in terminally correctly like this “global_unicast_prefixes”
MikroTik bug. I think I need to add quotations. I’ll fix it.
And one last thing:
I see you’re doing away with the IPv4 ICMP raw filtering. Do you no longer see a benefit to filtering by ICMP types? Also, I do not see any further ICMP accept rules. Is that somehow accepted in the implied “accept everything else from LAN/WAN” rules?
Yes. The kernel by default rates limit ICMP/ICMPv6 anyways and hence those rules are redundant and a waste of CPU. All ICMP/ICMPv6 is accepted, let the kernel handle rate limiting.
Don’t miss the new RFC6890 section 🙂
Yea I see the RFC6890 blackhole section, I think that part is awesome. I was doing that with my public subnet but using it for the RFC6890 is an excellent idea.
In regards to ICMP, I get the rate limits but what about the allowed ICMP types? Arent there some deprecated and malicious ICMP types that should not be allowed? Or I guess in this case, you only allow specific ICMP types?
Yeah, I will edit the RFC6890 section and say “Inject these rules into any router/L3 switch that has a routing table” – Makes perfect sense if you really think about it.
There are deprecated ICMP types, yes, but I haven’t seen any hard evidence of them doing any damage if they aren’t blocked, and even if somehow they could, again they are rate limited. So why waste CPU power anyway. As long as everything else is properly configured, the network should be secure.
You’d need ICMP filtering maybe for DoD/DARPA stuff or something, but eh, not at ISP level in my opinion. I’ve removed all ICMP filtering in my own network and my home routers as well.
Like ICMP type 4 source quench for example. Thats deprecated and is used in some attacks from what ive read. Seems like nothing but bad news
https://www.dell.com/support/kbdoc/en-sg/000151666/force10-security-advisory-icmp-attacks-against-tcp
I think I read this, this morning and it seems as long as you ensure 1500 MTU/MRU end-to-end in all directions/interfaces/paths, you should be safe:
https://twitter.com/DaryllSwer/status/1512702950418030593
I’ve revised the ICMPv4+ICMPv6 filtering rules from scratch using IANA as a source, you can deploy them on your network.
Previously, I couldnt believe how much garbage this rule was collecting.
#This rule should be redudant as we are now routing RFC6890 to blackhole directly and hence I am commenting it out#
#add action=drop chain=forward comment=”Drop tries to reach not public addresses from LAN” dst-address-list=not_in_internet in-interface-list=LAN out-interface-list=WAN#
It was every single router regardless of type of network, there was always tons of garbage. And I couldnt believe there was that much of it, everywhere. My guess is random misconfigurations and/or crap device code.
I then implemented the blackhole routes and WOW….its mostly all gone now.
And I say “mostly” because there’s one small caveat I noticed. One of my sites has a failover which is a double NAT through another provider. With the failover WAN IP being in the 192.168.x.x subnet, bandit packets are still hitting the above rule. Which makes sense if you think about it. Its a minor issue, not that big a deal, especially on a site of its kind. But thought it was worth mentioning.
It’s not just misconfiguration. For unknown reasons my personal Windows 11, Debian Based, iOS, macOS devices all originate such packets. I never found an explanation.
That’s expected behaviour in your specific site:
More specific route is always preferred over less specific route. I’d leave it be, not much harm that could happen there.
Hi Daryll. In terms of netmap. The way I understand it in my laymens terms is that if one has a subnet of fixed public IPs being netmapped to a larger group of private IPs, what happens is what I call a slice or jump pattern of assignment. Initially I thought Okay for a 256 block of public iPs, the first private 256 private IPs are assigned tot he first public IP. Wrong, Its the 1,257,513 etc private IPs that get assigned to the public IP. So its fair to say that the same block of private IPs (via slices or jumps) always gets the same public IP. Hope that helps.
I already knew the netmaps ensure 1:1 mapping, i.e 1.1.1.1 netmapped to 100.64.0.7 will persistently stay the same until reboot or similar. Which is perfect for P2P/STUN/ICE/WebRTC/TURN. But the question is: Why does netmap public/24 works with private/8 for example? The Linux Man page suggests it shouldn’t.
Edit: Wait a minute, this is “Anav” from the MikroTik forums, ain’t it? I’m leaving just going to leave this here.
Hello
Thats a great work
I have a question, what is the real purpose of loose tcp tracking?
Is it other tracking with the original connection track ?
Loose tracking = yes means don’t pick up already established connections twice (or more). Saving CPU and resources.
Question regarding IPv6:
The biggest reason I have yet to deploy it yet is due to Mikrotik’s limitation in being able to simultaneously queue both IPv4 and IPv6.
How are you doing it? Is it easier since most ISP’s in India use PPPOE?
I just ran across the below from one of the big Mikrotik consultants using RADIUS via DHCP.
https://stubarea51.net/2022/03/30/webinar-deploying-ipv6-for-wisps-and-fisps/
With PPPoE, it is easier. But I think you would need to give persistent IPv6 PD assignments (which you should be doing anyways), and then Queue on a per prefix basis where a customer is behind each of them.
But if you’re going the DHCPv6 route – With Tik, there’s a problem. It can only hand out PD, but not addresses. Which means the customer will receive a /56 or shorter prefixes for LAN, but their WAN (Link prefix) will be null, unless you use a /64 on a per interface basis with SLAAC and configure the CPE to pick it up via SLAAC for WAN. But even then you’ll have a problem. SLAAC in Tik is not managed via RADIUS – So you won’t know which customer was assigned which address and so on.
I’d suggest talking with stubarea51 consulting firm and let me know if you find a solution. I’ll add it to my guide.
Matter of fact if you’re already doing DHCPv4, let me know the whole procedure (via emails), I’ll add that to my guide too – Like how did you set up DHCP Option 82, MAC binding, security. Did you use VRFs maybe? To repeat RFC1918 for different VLANs etc?
Hi Daryll
Thanks for this article
I have an idea about routing loop, What about add RFC6890 in routing rules with lookup only table, ip rout here only take this table to blackhole ?
The whole point is to route less specifics to blackhole. Which is applicable to both RFC680 blocks and also public pools.
What is lookup supposed to serve? I don’t see the need to possibly (if I understood you) create a blackhole only table?
Here is an example
/routing table
add disabled=no fib name=Blackhole
/routing rule
add action=lookup-only-in-table disabled=no dst-address=192.168.0.0/16 table=Blackhole
add action=lookup-only-in-table disabled=no dst-address=10.0.0.0/8 table=Blackhole
add action=lookup-only-in-table disabled=no dst-address=172.16.0.0/12 table=Blackhole
add action=lookup-only-in-table disabled=no dst-address=255.255.255.255/32 interface=BNG table=Blackhole
/ip route
add blackhole comment=Blackhole disabled=no distance=1 dst-address=0.0.0.0/0 gateway=”” pref-src=”” routing-table=Blackhole scope=30 suppress-hw-offload=no \
target-scope=10
I don’t see any reason to use a separate table. If anything this would probably increase CPU usage as now it has to manually lookup for each subnet.
Hi Daryll,
First of all: thank you so much for this extensive, well documented piece of work!
I’m used to building networks with cisco and juniper equipment but fell in love with mikrotik stuff, built my own little ipv6 only AS with it and am now in the process of optimizing basic stuff. That’s when I arrived here – and rethought my firewalling from the ground up thanks to your great work! So thanks again!
I do have one question though: Running ROS7 and changed from stateful firewall filter rules to modified versions of your raw filters. While this did the trick to get rid of IPv4 connection tracking, I still have “living” entries in ipv6/firewall/connections – without any filter rules. And there is no ipv6/firewall/connection/tracking submenu to disable it manually. Am I missing something or is it not possible to turn off connection tracking for IPv6?
Second, more general question: you seem to have updated this blog entry on June 29th. Is there some kind of changelog I could refer to for your changes? 😉 Otherwise I might have to download this entry to a local git repo to stay up to date 🙂
Thanks again for your terrific work and best regards from Germany,
Johannes
IPv6 connection tracking is automatically disabled on both ROSv6 and ROSv7 if there is nothing in
/ipv6 firewall filterormangleornat(66). If it’s still tracking, then I suggest you contact MikroTik support, as that sounds like a bug.Minor typos were fixed on June 29th. I cannot keep changelogs of such a large documentation, but if you know of any WordPress plugin that can automate the job of a change log, then please by all means, do share, I’ll make use of it.
I’m glad my guide was of use to your network. Furthermore, I hope you follow all the BCPs and BCOPs for your network to ensure a fully conforming and homogenous network!
Are you positive you didn’t get this the wrong way round? Loose tracking = off, i.e. strict tracking enabled, will cause already established connections not picked up?
Can you please expand on this?
I would expect this setting to correspond to the netfilter loose tracking mode which has less sanity checks around NEW state packets, penultimate FIN packets, etc.
Loose tracking enabled = “non-strict” tracking. Lose tracking disabled = strict tracking. I am positive.
You find elaboration here.
while this was very good, sfq does not fix bufferbloat. fq_codel/cake do. the test you used measures fq not queue depth (aqm). try a packet capture on that test.
Hi Dave
A few points to note and consider:
1. This article dates back to 2021 back on RouterOS v6 when fq_codel/CAKE did not exist on MikroTik
2. I did not claim that SFQ “fixes” bufferbloat, only that it reduced
3. I do not have the time to test QoS any further, if you have hard data/configuration used on a BNG device serving a minimum of at least 200 users, feel free to share the config, screenshots, and guidelines. I will consider adding that to the article and credit such a section to your name.
Furthermore, I’m not a specialist in QoS, so I’m not sure what you mean by “fq not queue depth (aqm)”, but at the time of testing, the device had around 1k customers with at least minimum 1Gig traffic going in/out.
There was a lot of uptake of fq_codel after it arrived in mikrotik. Very long thread over here about sfq vs cake in particular:
https://forum.mikrotik.com/viewtopic.php?t=179307#p885613
As for a guide, I will try to find someone deploying. Basically on cpe we are seeing cake ack-filter bandwidth XMbit diffserv4 on a simple queue on the up, and I don’t really know what is used on the bng side (seeing preseem/libreqos/cambium/
Apologies for misconstruing your statement. FQ is what the tests measure you used, queue depth (managed via AQM), is bufferbloat. FQ bypasses the queue-building flows.
Yes, I know MikroTik added fq_codel/CAKE etc in RouterOS v7, but back in 2021, RouterOS v7 was not production-ready and hence was not tested. I lack the time to implement it on my own personal network as well, but hopefully, I’ll get to it eventually.
Most network operators in APAC that are using MikroTik a lot for BNGs, just use whatever MikroTik defaults come with for the queuing algorithm, so SFQ, PFIFO etc. They do not spend in-depth testing and research into what method works best for their network, at least on BNG level – This was the main reason for SFQ as I observed it “just works” even if not perfect. There’s a psychological factor at play, details here.
Ah, you mean, the “bufferbloat” test from DSLReports? Well, I can update that with a more proper web-based bufferbloat test site, sure, but I’ll need the “guide” though (config, data, screenshots, explanation to the reader etc).
Feel free to email me directly for further discussion or message via my Telegram (both are on the left sidebar at the top).
Hi Daryll
i had an idea about nat.
Why you add not_in_internet at dst-address
is not enough to add the same src-address in dst like this example ?
/ip firewall nat add
action=netmap chain=srcnat comment=”CGNAT rule” dst-address-list=!cgnat_subnets ipsec-policy=out,none out-interface-list=WAN src-address-list=cgnat_subnetsto-addresses=103.176.189.0/25
not_in_internet address list contains all the RFC6890 subnets including the CGNAT subnet range in aggregated format.
cgnat_subnets only contains either supernets or just the /10 subnet.
That is why we need not_in_internet.
In your Edge Router Firewall section, I notice you’re now fasttracking stateless traffic.
#Filter rules for FastTracking stateless traffic#
/ip firewall filter
add action=fasttrack-connection chain=input
add action=fasttrack-connection chain=forward
add action=fasttrack-connection chain=output
But since connection tracking is disabled on Edge Routers, isnt all traffic in essence Fast Tracked by default? It sounds kind of redundant to me but im obviously missing something.
FastTrack never works “by default”, FastPath does under limited conditions, for which if you’re using firewall address lists, FastPath is out the window as well.
And hence for this reason, we manually “FastTrack” the traffic through the rules above. But I recently found it’s logically more efficient to do this in the mangle table and cleaner. I’ll update the article itself, but here’s the snippet:
/ip firewall mangleadd action=fasttrack-connection chain=prerouting
add action=fasttrack-connection chain=output
You did explain very well.
Thanks for the feedback!
Hi Daryll.. I’ve followed your guide in MTU about configuring RFC 4638. I’ve set the MTU and MRU to 1500 in the PPPoE Server of Mikrotik, but I can only achieve a maximum of 1492 MTU. I’ve double checked already the MTU of OLT and Mikrotik with the OLT MTU set to maximum value of 2000 and Mikrotik router MTU of 1500 and L2 MTU of 2000. I’m not sure what’s going on as for why is it not working. The ONUs are Huawei HG8145V5 or maybe the modem is not capable of RFC 4638
The BNG L3 MTU should be 2000 on the physical port to match OLT L2/L3 MTU 2000. The customer MikroTik router L2 MTU maxed out but L3 will be 2000 to match OLT. ONUs should be bridge mode, but some ONUs even in bridge mode don’t support baby jumbo frames nor RFC4638. Also if you have switches between BNG and OLT, they all need proper MTU config. Follow MTU section sample.
Migrate to DHCPv4/v6 to avoid MTU problems.
Hey Daryll,
I have just noted that you took both rules from here.
Is it just copy&paste (like me 🙂 ) or any reason to have both?
If I’m not mistaken, anything that could be caught by the second rule is caught by the first rule anyway.
MikroTik copied it from here.
The second rule is definitely redundant, however with that being said, I’m planning to remove these two configuration parameters completely from the guide.
The reasoning being such configuration only makes sense for SOHO/Minuscule networks no bigger than my home lab 🙂
For production networks we should be using FastNetMon for detection + escalation and a third-party DDoS scrubber. The rules above do absolutely nothing when you’re hit with a real DDoS and more than likely block legitimate traffic in large networks.
> MikroTik copied it from here.
I know that 🙂
I read it up and down and up again but still searching a 100% explanation for time/count in the explanation of bust in dst-limit.
> SOHO
that is my case 🙂
> For production networks we should be using FastNetMon
so this https://forum.mikrotik.com/viewtopic.php?t=124958 or https://github.com/elmaxid/Fastnetmon-MikroTik-Plugin
I have a strange issue – maybe somebody has an idea .
I have a CCR2004 with PPPOE set up. 10gbps connection to the internet and 10gbps link to local peering.
There is a 10gig connection at the DC between the fibre network operator and the CCR2004
Home has a 250mbps fibre link connected via ONT to the fibre network operator.
On client side, when doing download on cable, full 250mbps is achieved. When trying 5G wifi you get 150mbps download and 250mbps upload. There is no wifi interference at all. (Local downloads on wifi (onsite NAS) is achieving download speed of 700mbps)
Strangely, when downloading from a IPv6 address (on wifi), we get full 250mbps. It looks like something is causing poor performance on ipv4. Client CPE MTU is set to 1492 and on CCR2004 the MaxMTU and MAX MRU is left blank in the PPPOE Service config.
Why is MTU not configured end-to-end correctly, including RFC4638, as per the guide? Fix the MTU configuration.
Next, make sure CGNAT is correctly configured, routed to blackhole as per the guide. Reboot CGNAT box during off hours and test again.
Additionally, it sounds like you’re using a single CCR2004 for both edge routing and customer downstream delegation, stateful-ness on the edge is a bad idea to begin with, also explained in the guide.
Hello
Client end only goes to 1492 so should I rather set MAX MTU and MRU to 1492 on the BNG as well?
Dont use CGNAT for the clients as they have static IPv4. Blackhole routes set up for those IP4 ranges
No. MTU/MRU should always be 1500 on the PPPoE server, and the underlay MTU for the physical Ethernet and SFP cages would be jumbo frames, along with the VLAN L3 MTU and also any VPLS interfaces you may have.
The underlay network should carry jumbo frames, end-to-end, network wide.
Client doesn’t matter, even if it’s limited to only 1492. RFC4638 will do its job via the “PPP-Max-Payload” tag in the PPPoE negotiation procedure.
Feel free to reach out to our public community here.
My ISP actively uses the MTU of 1492, either as AS7303 or its upstream AS262589. Some sites in Brazil are dropping on 1500. Is one of the two filtering ICMP, or is there a equipment set on 1492, damaging PMTUD?
The common user will never complain about this, as some modems in NAT are hardcoded on 1490. i.imgur.com/aM3LwDV.jpeg
Ask your ISP(s) to deploy RFC4638, point them to this guide. I can’t help you to change the mind of your ISP, you and other customers in your country need to raise complaints.
I believe you would like to take a look at this Feature suggestion to MikroTik RouterOS.
URPF rp-filter per interface
https://forum.mikrotik.com/viewtopic.php?p=1013534
I liked very much of your article!
I certainly will need to read an re-read it a few times to absorve all that.
There is a long-standing debate on uRPF vs rp-filter.
1. rp-filter only exists in the Linux kernel and OSes that uses the Linux kernel for networking control/data plane, it does not exist on major vendors like Cisco, Juniper etc who uses custom code for both the control and data plane.
2. uRPF is not officially supported on the Linux kernel, but it is supported on major vendors.
RFC 3704 only defines RPF, but never defined rp-filter:
https://en.wikipedia.org/wiki/Reverse-path_forwarding#Filtering_vs._forwarding
Regardless of the difference, it would be nice to have feasible mode rp-filter (or uRPF) with proper CPU/memory optimisations to avoid issues.
Even Juniper doesn’t support feasible mode as of now.
My point is to have the possibility of disabling rp-filter per interface.
On a BNG that has a single uplink PTP, no issues on activating rp-filter=strict
But on a BNG that has more the one uplinks, one to CDN router, other one to CGNAT, other to BGP-Border-A, another to BGP-Border-B, assimetry certainly will occur.
And because os those just a few interfaces we need to disable or put in loose mode the global cenário of the box(all interfaces, including subscribers).
So…
“Hey Mikrotik, allow-me to disable per interface the rp-filter.
Just that.
I know what you mean, but I don’t see that happening on MikroTik. You need to convince MikroTik, not me 🙂
What about some coordinated effort from several guys to “help” them to understand the need?
Should have no hope on that?
If you’re looking for a campaign leader or group to teach MikroTik staff on the importance of per-interface rp-filter (or anything else of the sort), I’m afraid I’m not the right person for the job nor do I share an interest in such objectives.
I have a lot on my plate already, I don’t have the mental capacity, time nor schedule to go chasing after MikroTik to implement a 20-year-old feature.
About DST-NATing packets that reach public IPs to a loopback.
You mentioned that you used this solution to fix routing loops.
To be frank, I don’t see that methodology as the prettier. ha-ha.
But I’ve already used something close to that.
The motivations were different! Geo-location!
Beyond all the cadastral efforts, latency triangulation has a high impact on the geolocation databases. I can say that by experience.
Hosting a ripe atlas probe and/or anchor will accelerate very much the organic corrections of geolocation database.
But it(probe) needs to be able to ping and traceroute to the IPs.
And this is the part I would like to listen to your opinion.
Between our guys, we reached two possible solutions:
a- DST-NATing everything that comes to Public IP Addresses to an IP on a loopback.
b- Putting all the 8, 16, 32 /32 public IPs addresses on a loopback.
To be sincere, I consider both methods ugly… But both works.
My reference until now make me think that “b” is a bit better.
We can create a dedicated loopback to that and do some work with firewall rules matching interface to avoid interaction with other packets flowing.
Have an opinion about that?
1. I am planning to remove/update the dst-nat loopback method, these days I prefer blackhole routing of the CGNAT public range on each CGNAT box, this means zero loops.
2. I may still enable dst-nat loopback hack only for ICMP, this is for fun, bells and whistles, to allow customers and measurement probes to be able to properly ping your CGNAT public range. Not mandatory, but “cool”.
For Geo-location, you should be following the current standards based on RFC8805. Use this tool to verify your inetnum and inet6num objects are complying with RFC8805. You can test the tool with my IP ranges to see how it works.
Watch this video by Massimo Candela from NTT on the subject.
Yep! I know pretty much geofeeds.
But it still doesn’t have too much traction.
P.S.: Unfortunately, most of our customers depend on renting IPv4 addresses.
Yep… This is a shit. But is the intermediary solution until buying their own blocks.
And, dealing with that kind of issues very frequently, we created a sequence of doings that usually solve issues with geolocations and CDN distributions involving(non exhaustive) things like Geofeed.csv + Whois remark, GeoIDX on IRR, Internal Recursive DNS Server IP Addresses sharing same AS-Path than the eyeballs IP Blocks…
But, in fact, the most efective action is related to Latency triangulation.
Atlas probes, NLNOG RING, and others…
And responding to ping, traceroute, and some other probing that comes from them.
And exactly because of this probes I asked you about it.
Thanks anyway.
Geofeed and the method I described here works well. Within 15 days, all major GeoIP DB providers will show up-to-date location information. Whenever I received a new IP block, within 15 days, it’s fully-updated on the Geo providers.
I’ve spoken to one of the CEO/Founder of a GeoIP DB company, and they agreed my method is valid and effective and shared they’ve received many emails of people who followed my template/steps.
This document is gold, I couldn’t ask for more I hope a lot of documents on the internet will be like this, because of this document I was able to polish my Proof-of-concept dual stack deployment and the management is happy with the result, our POC is now out of beta stage and soon will be launched with selected PoP in our network.
Hello
I’m glad my work has been of great help to you. I’d appreciate it if you could support my work here.
Hi Daryll,
Does this still works???
In my Case we have ROS6.49.8
/ipv6 dhcp-server binding;
:foreach i in=[find server~”pppoe”] do={
make-static $i;
set $i comment=[get $i server];
set $i server=all;
}
It probably no longer works. If you can write a new script let me know. I’ll update my blog article.
“Blocks inbound ports based on the false logic of “protecting” the customer
Port blocking does nothing to improve security, it only breaks legitimate traffic such as apps or games that use various methods for VoIP”
I strongly disagree. We have a filter on the access-router of our POPs.
To filter a well known list of port, inbound only, for example, 22,23,80,443,1723 to protect the management part of the customer’s routers.
We open on request by the client, and we have an outgoing filter to remote 135,137-139 for example… and we match a lot of traffic.
That is a stupid practice, and if I was subjected to such treatment by an ISP, I’m taking it to court and in many countries, the court will be in consumer’s favour in such cases.
It’s the customer’s responsibility/job to filter their routers, hosts etc to protect their network on their side, with their firewall filters from the public internet—Why is the ISP playing firewall here? What legal justification do you have to block those ports, when customers paid for their IPv4 addresses and IPv6 PDs?
ISP’s job is to provide transit capacity and pathways to the public internet, not play traffic police. I’m not sure what the laws and regulations are like in your country of operations, but I certainly wouldn’t want to live there, if the laws permit ISPs to play traffic police, this sounds more like communist China to me.
Well, we are ISP in Italy since 2011
we never had a single complaint about filtered ports inbound/outbound. They are put to stop spreading the most common malaware. If a customers asks for unfiltered ports, we open them to him, and they are a VERY litte percentage. Since nowhere writes in our legislation that I need to give you open ports or unfiltered network, we put into our contract.
I appreciate your work, but I just throw my opinion to your point.
Regards.
I do not have knowledge of Italy laws and regulations, so I cannot comment on the legality of it. But if the consumers have no legal protection for “filter-free” internet access, on residential lines and/or commercial/enterprise lines, I’d be gravely concerned as a professional in this domain.
That is because most customers are not network engineers, they aren’t technical persons, you know this. It’s not the job of the customer to reverse engineer the ISP and demand the ISP to implement best practices, net neutrality compliant network implementation etc, this is the job of the ISP’s board of directors, management, and engineering team and their governments, to do their due diligence.
I am a strong and vocal supporter of net neutrality-compliant network implementations, including net neutrality-friendly traffic shaping (example bufferbloat control via LibreQoS), therefore network traffic filtering topics, from my side, is driven by my political standpoint on the matter—for context.
I will conclude this with food for thought:
When you buy DIA (IP Transit) from Cogent and Telecom Italia Sparkle, do they perform port-blocking/filtering/traffic policing against your traffic inbound/outbound? Would you prefer if they did?
Hello…
well in Italy the regulations are so strict that for example since november 2023 we MUST filter the contents on the our contracts, we MUST implement an adult filtering dns system to filter by default the internet connections, to protect the people with less than 18yo. The customer need to explicity ask to remove the filter.
When we sell lines to residential customers, we filter them by default, and allow a quick opt-out policy if needed (if they have the public IP, since we also offer lines in CGN).
Enterprise customers are unfiltered if they ask to. We just inform them.
About transit, the transit, by default, need to be unfiltered since we are ISP, not an end user.
DNS/SNI based filtering, is something that, unfortunately is being enforced at a global scale by many governments, this is leading to fragmentation of the internet ecosystem, if Telcos, ISPs, WISPs, globally don’t come together, we’re in deep trouble in the coming decade. It starts with “adult filtering” and then moves to censorship of the press, censorship of journalism etc 🙁
However, as a network engineer myself, you may have noticed, I never mentioned DNS/SNI filtering in my guide, this is because:
1. It does not violate the end-to-end principle of IP Networking.
2. It does not break layer 4 reachability.
3. No packet mangling/molestation.
4. Zero impact to ephemeral ports for UDP, STUN/TURN/Hole punching applications.
5. Network operators are forced by governments, because, well, governments like to play tech-bro, unfortunately.
6. Customers can use DoH/DoQ/DoT/DoH3 of third-party recursives to bypass—But even this is becoming a shit-show, see references below:
A. https://torrentfreak.com/cloudflare-dns-has-to-block-pirate-sites-italian-court-confirms-230403/
B. https://torrentfreak.com/dns-resolver-quad9-loses-global-pirate-site-blocking-case-against-sony-230308/
My recommendation, is to educated your customers (via website? Blog? FAQ? Email?) to have a firewall configured on their CE (customer edge routers) for Layer 3-4 protection (IP, Ports, TCP/UDP/Other L4 protocols). Give them, routers with pre-configured templates. Most CPEs already have stateful firewalling enabled by default by OEMs anyway.
On ISP side, only few ports, in my opinion, have valid use-case for blocking by default with ability for exception on request, port 25 (because of email spammers) and in some countries, SIP ports (call scammers etc).
Side note:
I hope you’re providing native IPv6 with BCOP-690 compliances to your customers.
Hello, would it be possible for you to make a small diagram about the architecture of these configurations?
The configuration principles and examples are largely topology-independent. “Edge router” configuration is applicable to any router or layer 3 devices that’s stateless, “BNG” configuration is applicable to any router or layer 3 devices that’s stateful.
god bless u sir
Hi Daryll.
I have a couple of Mikrotik routers in my home network, so I was very interested in what you said about Router Advertisements being used on all interfaces by default.
However I’ve just done some packet captures, and these seem to paint a different picture to what you described. Specifically my testing shows that while the “ipv6 nd” settings define the Router Advertisement parameters (RA interval, RA lifetime, etc), the decision about whether or not to send Router Advertisements is based on the IPv6 address configurations.
If you run “ipv6 address print” you can see all the configured interfaces and whether or not they are configured to send Router Advertisements.
In particular it is worth noting:
* IPv6 Link-Local addresses (which are assigned to interfaces automatically) don’t generate Router Advertisements. The “export” command doesn’t list these.
* IPv6 addresses that have been added with advertise=no don’t result in Router Advertisements. The “export” command shows “advertise=no” for these addresses.
* IPv6 addresses that don’t have advertise=no will generate Router Advertisements. The “export” command doesn’t show any “advertise” parameter for these addresses.
Rather than advising people to disable the “ipv6 nd” configuration, I think the advice should be to add “advertise=no” to IPv6 addresses that you add, unless you actually do want Router Advertisements sent?
Thanks,
Nick.
Are you on Telegram? Chat with me over there:
https://t.me/NetworkOpsCentral
Or just email me.
I need in depth configuration dumps of your setup and topology diagram + PCAPs and how those were obtained to verify this.
Hi Daryll,
I found your post very useful . I try to follow all the steps you mentioned . I love it . and deployed into my ISP network. But i am still having some confusion . I have switch connected between the path from PPPOE NAS and PPPOE_CLIENT (Huwaei_ONT) . From client end i do the test ping google.com -f -l 1452 without packet fragmentation . On Huwaei ONT wan i have setup MSS of 1480. I want to know what will be the best MSS for that client . I found it could be something like 1452 or less but confuse.
Below is my Simple Topology.
PPPOE-Server>VLANS>Ethernet>LACP>Switch>OLT>ONT (My switch Doesnot support MTU Greater than 1600 and also carry diffrent vlans for BGP(ISP-UPLINK) etc Please suggest what will be the best solution on PPPOE_NAS(MIKROTIK)/ PPPOE_Client(Huawei_ONT).
The proper solution is to deploy RFC4638 on provider side as per my guide. 1600 MTU on the switch is more than sufficient for client to get native 1500 MTU over PPPoE.
TCP MSS clamping should be disabled in a production network. Use proper MTU.
Hey Daryll
Things like NAT-Endpoint-Independent and NAT-PMP came into RouterOS.
Other things also.
Do you think this should be included in this optimization guide?
I’m using EIM-NAT myself in CGNAT production and in home lab. I’ll update the guide to include this next year. But MikroTik EIM-NAT is not on par with Cisco and Juniper as it only supports UDP and not TCP. I suggest you reach out to their official support and ask for Cisco-grade EIM-NAT.
NAT-PMP is 10 years too late, we’re in IPv6 era now. The overhead that comes with NAT-PMP is better spent on something like 464xlat or MAP-T.
Volume of data with CGNAT logging using Traffic Flow without BPA.
We know that RouterOS does not support Bulk Port Allocation.
And I’m a little curious about the resulting storage volume for this logging scenario through Traffic-Flow without the Bulk port Allocation feature.
From what I understand, it uses NEL – NetFlow Event Logging, but does not use Port Block Allocation / Deallocation events. In other words, each new connection created/closed is a new LOG entry.
Daryll, can you give an estimate of the daily log volume for a real CGNAT scenario, providing a reference for the number of users or Gbps passing through the CGNAT box?
I don’t think anyone can give reference number as this is a case of complete randomness across different networks and demographics.
But here’s what I do know:
If I have 1000 customers behind single BNG, and all 1k customer router have enabled IPv6 for WAN and LAN, I’ve observed 80-90% traffic for 1k customers going over IPv6 instead, especially for CDN/Content traffic. Remaining 10-20% is CGNAT, with my netmap method.
Well… I can share some reference of CGNAT scenarios using A10 and NFWare, which could provide a basis for comparison.
In scenarios here in Brazil, with Dual-Stack IPv6+IPv4, IPv6 being reasonably well deployed, and IPv4 in CGNAT.
In ISPs with CDNs caches within their own network, which means a certain prioritization of access to cached content.
And also with By-Pass to CGNAT of what is accessed by subscribers to these CDN caches (OCA, GGC, FNA) and also internal servers such as their own recursive DNS.
Configuring BPA to:
– Block of 768 ports in the first allocation.
– Additional blocks of 256 ports.
– Maximum 2048 public ports allocated to each subscriber.
– Connection timeout respecting RFC timeouts (Ex.: 2hours and 4 minutes to TCP).
– Synchronized ranges allocated between TCP and UDP for the same subscriber.
In a network with approximately 15K clients, the box generates a volume of 150-180 Megabytes per day. Resulting in 15-30 Megabytes compressed.
I can also share that in similar scenarios (15K subscribers with IPv6 and CDN caches) where the ISP had very few public IPs available to use in CGNAT, and we had to be more limiting on BPA settings:
– Unsynchronized TCP and UDP range.
– 256 ports for the initial allocated block
– 128 ports for additional allocations
– TCP timeout in 30 minutes.
The volume of daily LOGs increased A LOT!
Approximately 800-900 Megabytes per day. And 120-150 Megabytes compressed.
And it is precisely because of this huge difference that I am curious to see how much volume a log per-connection scenario would bring.
If you find out the data, let me know as well.
Keep in mind having such short TCP timeout value will affect multiplayer games that rely on TCP for state maintenance etc (gameplay data is over UDP of course).
It sounds like your customer routers on all 15k didn’t have IPv6 enabled for the LAN though.
At some point I’m starting to think it’s better to invest capital into buying v4 block after market to avoid CGNAT logging issues. Of course it’s not cheap.
“such short TCP timeout”
I believe you are talking about 30 min…
Yep! Is a bug in the ass…
But was the solution we found to so many connections abandoned connections that were present on ConnTrack.
Obs.: This ISP rented some IPs and as we changed the BPA confs it came back “normal” logs volumes.
But with 2 hours and 4 minutes (RFC5382 REQ-5) there are no pain (support tickets from subscribers) related to that..
Don’t forget to route the public pool to blackhole on the NAT box. This keeps the connection tracking table clean when user is offline or connection breaks etc. In addition to the RFC6890 blackhole.
3 years ago when I tested 2 hour timeout, it breaks CoD Warzone consistently. I stuck with 24 hours ever since + blackhole.
Do you, by chance, know how one could leverage L3HW offloading from CCR2116/2216 and explain the tradeoffs?
I may be wrong but it looks like CCR2116 only L3HW offloading NAT masquerading so netmap is totally handled by the CPU. About queues, L3HW offloading only allows for WRED for the moment so no FQ_CODEL.
MikroTik generally has a CPU + ASIC model of packet forwarding, so there always will be a mix of both, if you need pure ASIC forwarding, then the general recommendation is to opt for a different vendor.
NAT L3 offloading should be for both src and dst NAT, regardless of action type. I’m not sure if perhaps MikroTik support clarified to you that they only offload masquerade?
Queues such as simple queues are CPU bound and will benefit from FQ_Codel, for physical ports, it’s unclear, as I said MikroTik does CPU + ASIC, so it may be that FQ_Codel on PHY ports will be used for CPU bound traffic, and regular legacy WRED will be used on ASIC traffic at line rate.
Currently, there’s no ASIC that natively supports FQ_Codel:
https://x.com/DaryllSwer/status/1798117348437811634
Also, please read the announcement at the top of this blog article, it is no longer being maintained.
Hello Daryll, congratulations in advance for such excellent work.
We want to ask you about the functions that you perform in the BNG or PPPoE SERVERs and we understood that it was not good practice or it was not advisable to perform NAT on a PPPoE SERVER router with thousands of dynamic interfaces, since when the pppoe sessions disconnect and connect massively This negatively impacts the performance of the nat router.
What do you think about this, is it true?
If you require my services for proper consultancy, click here.
Thank you so much
Regarding CGNAT, is there any improvement in using 100.64.0.0/10 instead of RFC1918? Or would RFC1918 have somehow affected CGNAT?
You can either read RFC6598, or reach out to me for paid consultation.
Hi,
Nice work man!
Do you have any reason for not protecting your self from spoofing of your public ipv4 and ipv6 adresses comming from your upstream?
A small modification to the “allow all wan” rule in the edge router would do the trick,
and maybe an exception rule if you are renting out address space to multi-homed customers.
alt (1 new rule)
“add action=accept chain=prerouting comment=”defconf: Option accept friendly spoofer from WAN ” in-interface-list=WAN src-address-list=friendly_spoofers_subnets disabled=yes
add action=accept chain=prerouting comment=”defconf: accept everything else from WAN except self ” in-interface-list=WAN src-address-list=!lan_subnets”
alt (2 new rules)
“add action=accept chain=prerouting comment=”defconf: Option accept friendly spoofer from WAN ” in-interface-list=WAN src-address-list=friendly_spoofers_subnets disabled=yes
add action=drop chain=prerouting comment=”defconf: drop spoofed global from WAN” in-interface-list=WAN src-address-list=lan_subnets
add action=accept chain=prerouting comment=”defconf: accept everything else from WAN” in-interface-list=WAN”
uRPF/rp-filter will take care of that.
Hi Daryll, Thanks for this work
I have a question about interface queue
Should I change every interface queue or the WAN interface only, pppoe take default small queue in simple queue ? Should I change the LAN too ?
Everything
Love your article. I am try to comply with RFC2544 on VPLS pop for an enterprise customer. I set everything along the path from my BNG to Core with maxed l2mtu and 9k l3mtu. To pass the test, the customer must be able to pass 9k unfragmented packets. I noticed that if I set the MPLS interface mtu to 9k, it will fragment anything above 8996. If I set the MPLS interface MTUs to 9008 then it will pass 9k packets. My question is… If all the l3mtu on vlans and interfaces along the path are set to 9k, does that mean that setting the mols mtu above 9k makes some king of fragmentation internally that is not seen on the VPLS tunnel? What is the best approach here for MPLS MTU and VPLS l3mtu and PW L2MTU?
Thanks!
You need to carefully do MTU planning for underlay (PHY) and overlay (MPLS/VPLS etc) based on your network architecture end-to-end, so you’d need to test to make sure, you can transmit full frames from the Customer’s POV.
It’s been a while since I did MPLS on Tik, but IIRC, you don’t need to manually define MPLS interface MTU, if you’re confident the entire LSP has proper end-to-end jumbo frames, I look at some old config I did for clients in the past, and I didn’t define MPLS interface MTU, IIRC it defaulted to the underlying PHY L2MTU.
Is it possible to combine the EIM configuration with Deterministic NAT (i.e. fixed port ranges per internal IP address) on RouterOS? I know you said avoid Deterministic NAT, however I am wondering if technically it is possible on ROS with the primary downside being that the port range is restricted and that could lead to connectivity issues for clients.
Something like this for one client/host (100.64.0.255):
# udp, EIM
/ip firewall nat
add chain=srcnat action=endpoint-independent-nat to-addresses=192.0.2.1 to-ports=64466-65472 protocol=udp src-address=100.64.0.255 src-port=1024-65535
add chain=dstnat action=endpoint-independent-nat dst-address=192.0.2.1 dst-port=64466-65472 protocol=udp to-addresses=100.64.0.255
# tcp, same port range as TCP above
add action=src-nat chain=srcnat src-address=100.64.0.255 to-addresses=192.0.2.1 to-ports=64466-65472 protocol=tcp
# icmp
add action=src-nat chain=srcnat src-address=100.64.0.255 to-addresses=192.0.2.1 protocol=icmp
# hairpin
add action=masquerade chain=srcnat dst-address=100.64.0.0/24 src-address=100.64.0.0/24
Yes, something like that should work. Hairpin is broken on Tik, I have a pending support ticket with them for a long-time with no replies.
I’d probably prefer at least 6k ports or half of that if doing Deterministic NAT, coupled with native IPv6.
Thanks for the reply. In addition to the port count, two other things come to mind with my example config:
1) There is no rule matching src udp ports 1-1023, so I think I’d need another rule below the EIM rules for a catch-all of “all other udp” just like the TCP rule, except protocol=udp — agree?
2) I don’t understand how the EIM dstnat rule will map ports back to the private client:
add chain=dstnat action=endpoint-independent-nat dst-address=192.0.2.1 dst-port=64466-65472 protocol=udp to-addresses=100.64.0.255
So we’re matching anything going to 192.0.2.1:64466-65472 and saying dstnat that to 100.64.0.255, but what internal port will it translate to? It must be looking in the translation table for a match? If so, then I would think that even with a Deterministic NAT config, I could have just a single rule at the top to “enable” the EIF:
/ip firewall nat
add place-before=0 chain=dstnat action=endpoint-independent-nat protocol=udp
As shouldn’t that just allow anything through that has an entry in the NAT table to the appropriate internal host?
MikroTik’s EIM is a basic implementation, that doesn’t have that type of intelligence built-in, that you’d normally find on more expensive CGNAT products in the market. The hairpin being broken is proof that this type of logic doesn’t work, so you need separate rules per port-range/mapping. It’s unclear how the EIM dstnat knows where to map, likely it doesn’t, but you’ll need to test to find out. The same type of limitation is found in dst-nat netmap if we use unequal prefix length, how does srcnat works but not dstnat in reverse? In theory, it should do a lookup, right? But it doesn’t.
Port 1-1023 shouldn’t be part of any mapping in the CGNAT, unless the customer paid for public IPv4 and has IPv6.
Your requirements exceed what MikroTik can deliver. Or just deploy native IPv6 network-wide, move 80% of customer traffic to IPv6 (yes, doable, today, now), then get rid of deterministic NAT and stop worrying about ports on IPv4 NAT.
And finally, all these CGNAT solutions have problems, they lock L4 to TCP/UDP, SCTP, DCCP, UDP-Lite etc is just straight out blocked, leading to the ossification of global network stack to TCP/UDP (there’s a reason why QUIC over IP never happened).
IPv6 is the only clean solution to move forward. If you need professional consulting, feel free to reach out to me directly, we can discuss in more details.
Thanks Daryll!
I did some testing and the below EIM+Deterministic NAT configuration does seem to function.
/ip firewall nat
add action=endpoint-independent-nat chain=srcnat protocol=udp src-address=192.168.88.5 src-port=1024-65535 to-addresses=192.0.2.2 to-ports=64466-65472
add action=src-nat chain=srcnat protocol=tcp src-address=192.168.88.5 to-addresses=192.0.2.2 to-ports=64466-65472
add action=src-nat chain=srcnat protocol=icmp src-address=192.168.88.5 to-addresses=192.0.2.2
add action=endpoint-independent-nat chain=dstnat protocol=udp to-addresses=192.168.88.0/24
I started with the private client (192.168.88.5) initiating some UDP traffic to an external host from src-port 61831 which opened up port external port 64466. Then, from the external side, I sent UDP traffic to the IP+port 192.0.2.2:64466 and the dstnat rule did hit and I observed the traffic being translated to the correct private port (192.168.88.5:61831) and forwarded on to the host (confirmed with pcap). So that EIM dnat rule has to be looking up the proper port to translate to in the srcnat table.
However, I also noticed that when the EIM dnat rule is in place, whenever I send traffic to any un-tracked port it creates a new connection entry. It doesn’t forward it to 192.168.88.5, which is good, but it does still create a connection entry. So concern there is bad actors able to abuse/fill up connection table by blasting connections to all udp ports.
Anyway — comment if you wish, just wanted to post my findings.
Your finding is expected behaviour as RouterOS still uses large parts of vanilla Linux, vanilla Linux was never really made to be a “Kernel/Dataplane for networking products”, so what you discovered is just a software code implementation detail that was overlooked, and you’ll have a hard time patching that upstream which would percolate down the world over (if they ever accepted your merge request).
Ideally MikroTik would use Linux Kernel only for control/MGMT plane, and use eBPF/XDP (or DPDK/VPP) for dataplane for CPU-bound processing, this would give them 100% proprietary control over the implementation detail and also a massive performance boost.
Many of these behaviours are code-dependent and not specified in any RFC or standards documents (IEEE/ITU/IETF/MEF etc).
Long-story short, life’s just simpler without NAT — move to IPv6!